【iOS】内存五大分区
目录
- 堆(Heap)是什么
- 五大分区
- 栈区
- 堆区
- 全局/静态区
- 常量区(即.rodata)
- 代码区(.text)
- 函数栈
- 堆和栈的区别和联系
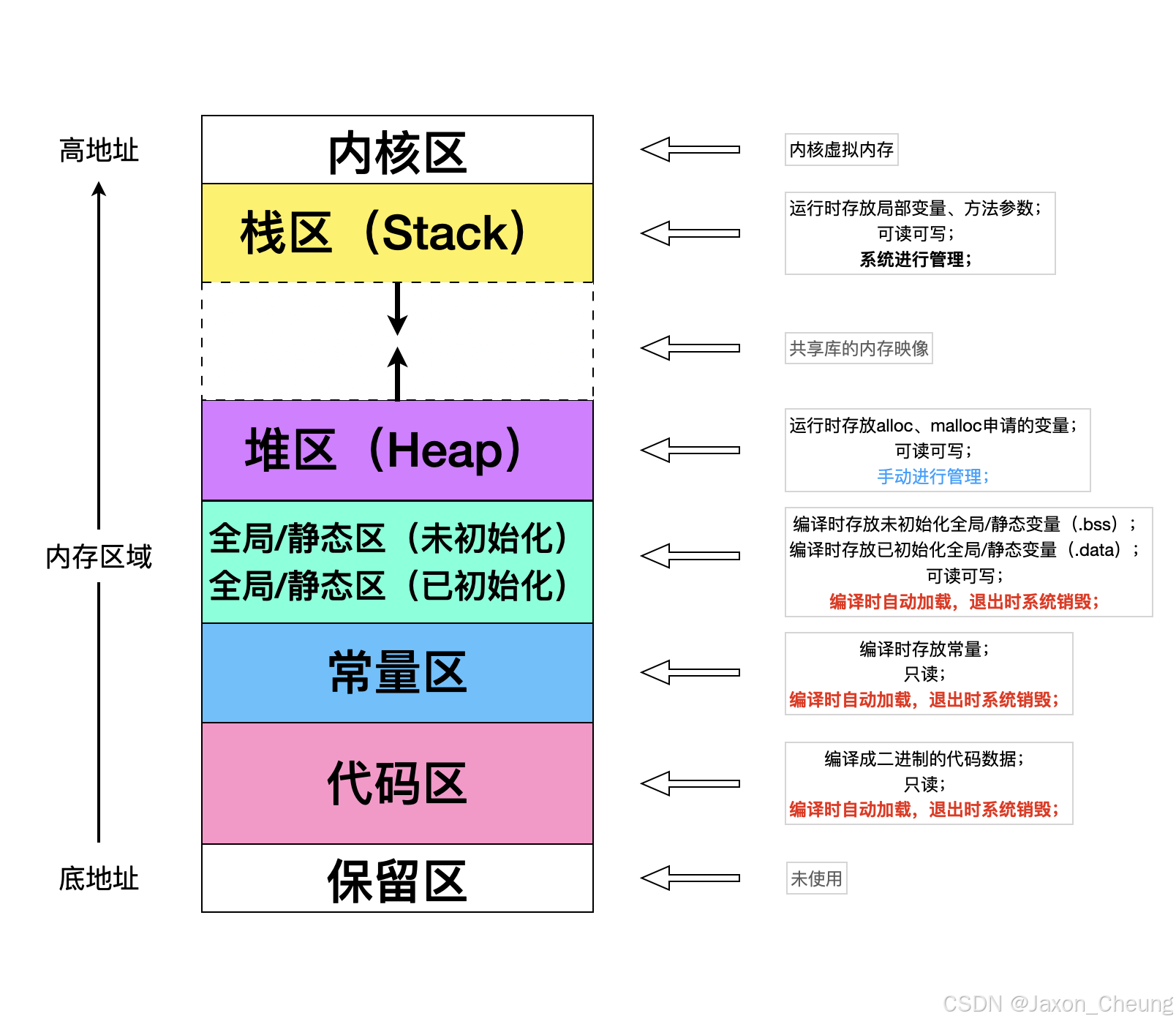
OC语言是C语言的超集,所以先了解C语言的内存模型的内存管理会有很大帮助。C语言的内存模型分为5个区:栈区、堆区、全局/静态区、常量区、代码区
一般情况下程序存放在ROM(只读内存,比如硬盘)或Flash中,运行时需要拷到RAM(随机存储器RAM)中执行,RAM会分别存储不同的信息,如下图所示:
RAM(random access memory):运行内存,CPU可以直接访问,读写速度快,但是不能掉电存储。它又分为:
- 动态DRAM,速度慢一点,需要定期的刷新(充电),常说的内存条就是指它,价格会稍低一点,手机中的运行内存也是指它
- 静态SRAM,速度快,我们常说的一级缓存,二级缓存就是指它,价格高一点
ROM(read only memory):存储性内存,可以掉电存储,eg:SD卡、Flash(机械磁盘也可以简单的理解为ROM)。用的多的:NandFlash(空间大,便宜),还有NorFlash(直接运行程序,读取速度快)
|_|
由于RAM类型不具备掉电存储能力(即一停止供电数据全没了,从新上电后全是乱码,所以需要初始化),所以app程序一般存放于ROM中。RAM的访问速度要远高于ROM,价格也要高
由于RAM不能掉电存储,所以我们的APP程序,刷机包,下载的文件等等,都是在ROM里面存储的手机里面使用的ROM基本都是NandFlash,CPU是不能直接访问的,而是需要文件系统/驱动程序(嵌入式中的EMC)将其读到RAM里CPU才可以访问
下面先了解一下堆是怎么存放和操作数据的
堆(Heap)是什么
堆是计算机科学中一类特殊的数据结构的统称。在队列中,调度程序反复提取队列中第一个作业并运行,因为实际情况中某些时间较短的任务将等待很长时间才能结束,或者某些不短小,但具有重要性的作业,同样应当具有优先权。堆即为解决此类问题设计的一种数据结构
|_|
堆(Heap)又被为优先队列(priority queue)。尽管名为优先队列,但堆并不是队列。在堆中,我们不是按照元素进入队列的先后顺序取出元素的,而是按照元素的优先级取出元素
这就好像候机的时候,无论谁先到达候机厅,总是头等舱的乘客先登机,然后是商务舱的乘客,最后是经济舱的乘客。每个乘客都有头等舱、商务舱、经济舱三种个键值(key)中的一个。头等舱->商务舱->经济舱依次享有从高到低的优先级
总的来说,堆是一种数据结构,数据的插入和删除是根据优先级定的,他有几个特性:
- 任意节点的优先级
≥它的子节点 - 每个节点值都
≤它的子节点 - 主要操作是插入和删除最小元素(元素值本身为优先级键值,小元素享有高优先级)
举个例子,就像叠罗汉,体重大(优先级低、值大)的站在最下面,体重小的站在最上面(优先级高,值小)。 为了让堆稳固,我们每次都让最上面的参与者退出堆,也就是每次取出优先级最高的元素

五大分区
栈区
栈是
一块连续的内存区域从高地址向低地址进行存储,遵循先进后出(FILO)原则栈区由操作系统在运行时自动分配,声明的变量过了作用域范围后内存便会自动释放,静态分配由编译器完成(自动变量
auto),动态分配由alloc函数完成函数内部定义的
局部变量、方法参数(方法中的默认参数:self、_cmd),都存放在栈区优缺点
- 优点:栈是由系统自动分配并释放的,不会产生内存碎片,所以
快速高效(栈使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放) - 缺点:查看官方文档,栈的内存大小有限制,数据不灵活,iOS
主线程栈大小是1MB,其他线程是512KB,MAC只有8M
- 优点:栈是由系统自动分配并释放的,不会产生内存碎片,所以
栈的地址空间在iOS中是以
0x7/0x16开头- (void)testStack { int a = 7777777; NSLog(@"a == %p, size == %lu", &a, sizeof(a)); NSLog(@"方法参数self:%p", &self); NSLog(@"方法参数cmd:%p", &_cmd); }
堆区
堆是不连续的内存区域从从低地址向高地址进行存储,类似于链表结构(便于增删,不便于查询),遵循先进先出(FIFO)原则
开发者需要关注变量的生命周期,如果不及时释放,会造成内存泄漏,只有等程序结束时由操作系统统一回收
存放的是OC中运行时使用
alloc、new创建的对象,C/C++中使用malloc、calloc以及realloc分配的空间,需要free释放优缺点
- 优点:获得空间灵活,分配内存较大
- 缺点:需手动管理,频繁的
new/delete势必会造成内存空间的不连续性,速度慢、容易产生内存碎片(堆则是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定,并不是一旦成为孤儿对象就能被回收)
堆的地址空间在iOS中是以
0x6开头- (void)testHeap { NSObject* object1 = [[NSObject alloc] init]; NSObject* object2 = [[NSObject alloc] init]; NSLog(@"object1 = %@", object1); NSLog(@"object2 = %@", object2); }
全局/静态区
该区是编译时分配的内存空间,在程序运行过程中,此内存中的数据一直存在,全局变量和静态变量的存储是放在一起的,初始化的全局变量和静态变量存放在一块区域,未初始化的全局变量和静态变量在相邻的另一块区域,程序结束后由系统释放
未初始化的全局变量和静态变量,即BSS区(
.bss)已初始化的全局变量和静态变量,即数据区(
.data)全局区的空间地址在iOS中一般以
0x1开头int bssA; static double dataB = 7.0; - (void)testExOrSt { NSLog(@"bssA == %p", &bssA); NSLog(@"dataB == %p", &dataB); }
常量区(即.rodata)
- 该区是编译时分配的内存空间,在程序运行过程中,此内存中的数据一直存在,程序结束后由系统释放
- 存放的是
整型、字符型、浮点、常量字符串等常量 - 常量只读
代码区(.text)
- 该区是编译时分配的内存空间,在程序运行过程中,此内存中的数据一直存在,程序结束后由系统释放
程序运行时的代码会被编译成二进制,存进内存的代码区域- 只读,代码段需要防止在运行时被非法修改,所以只允许读取操作,而不允许写入操作
函数栈
函数栈:又称为栈区,在内存中从高地址往底地址分配,与堆区相对。
栈帧:指函数(运行中且未完成)占用的一块独立的连续内存区域
应用中新创建的每个线程都有专用的栈空间,栈可以在线程期间自由使用。而线程中有千千万万的函数调用,这些函数共享进程的这个栈空间。每个函数所使用的栈空间是一个栈帧,所有的栈帧就组成了这个线程完整的栈
函数调用是发生在栈上的,每个函数的相关信息(例如局部变量、调用记录等)都存储在一个栈帧中,每执行一次函数调用,就会生成一个与其相关的栈帧,然后将其栈帧压入函数栈,而当函数执行结束,则将此函数对应的栈帧出栈并释放掉
以下是ARM的栈帧布局方式:
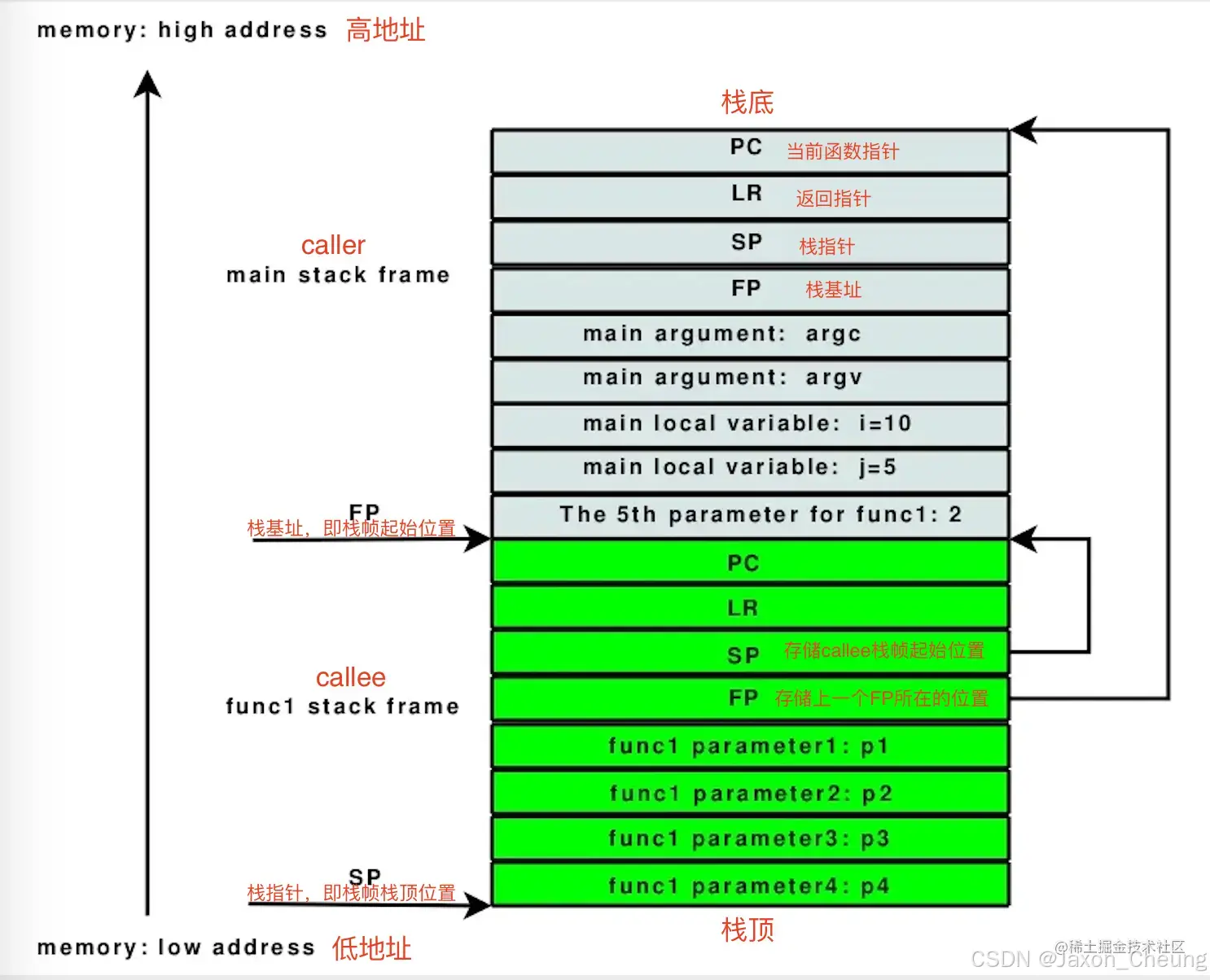
main stack frame为调用函数的栈帧func1 stack frame为当前函数(被调用者)的栈帧栈底在高地址,栈向下增长。FP就是栈基址,它指向函数的栈帧起始地址SP则是函数的栈指针,它指向栈顶的位置ARM压栈的顺序很是规矩(也比较容易被黑客攻破么),依次为当前函数指针PC、返回指针LR、栈指针SP、栈基址FP、传入参数个数及指针、本地变量和临时变量。如果函数准备调用另一个函数,跳转之前临时变量区先要保存另一个函数的参数- ARM也可以用
栈基址和栈指针明确标示栈帧的位置,栈指针SP一直移动,ARM的特点是,两个栈空间内的地址(SP+FP)前面,必然有两个代码地址(PC+LR)明确标示着调用函数位置内的某个地址
堆栈溢出
一般情况下应用程序是不需要考虑堆和栈的大小的,但是事实上堆和栈都不是无上限的,过多的递归会导致栈溢出,过多的alloc变量会导致堆溢出
所以预防堆栈溢出的方法:
- 避免
层次过深的递归调用 不要使用过多的局部变量,控制局部变量的大小避免分配占用空间太大的对象,并及时释放- 实在不行,适当的情景下
调用系统API修改线程的堆栈大小
堆和栈的区别和联系
1. 各自的优缺点?
- 栈:由编译器自动分配并释放,速度较快,不会产生内存碎片。优点是快速高效,缺点时有限制,数据不灵活
- 堆:由程序员分配和释放,速度比较慢,而且容易产生内存碎片,不过用起来最方便。优点是灵活方便,数据适应面广泛,但是效率有一定降低
2. 申请后的系统如何响应?
- 栈:存储每一个函数在执行的时候都会向操作系统索要资源,栈区就是函数运行时的内存,栈区中的变量由编译器负责分配和释放,内存随着函数的运行分配,随着函数的结束而释放,由系统自动完成。只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
- 堆:操作系统有一个记录空闲内存地址的链表。当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中
3. 申请大小的限制?
- 栈:栈是向低地址扩展的数据结构,是一块连续的内存的区域。是栈顶的地址和栈的最大容量是系统预先规定好的,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数 ) ,如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小
- 堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大