NEON做色域变化: 用单核性能无限逼近八核并行OpenCV
【前言】 本文版权属于GiantPandaCV公众号,未经许可请勿转载~
最近开始接触neon汇编,觉得这个东西在一些应用场景上好用,遂做些记录,分享下自己做的一些工作。
一、背景
色域变化是个老生常谈的问题,涉及到工程应用的方方面面,例如计算机视觉中常见的BGR转RGB,SLAM特征提取中的BGR转灰度图,安防监控中的YUV转BGR,车载显示中的NV12或NV21转RGB等。本篇博文主要讲两个操作,一个是BGR转RGB,一个是BGR转GRAY。
二、相关知识
Neon汇编是一种针对ARM架构处理器的一种汇编语言,是一种SIMD(单指令多数据)架构的扩展,它允许处理器同时对多个数据执行相同的操作,从而显著提高处理速度,特别是对于处理多媒体和图形数据。
Neon指令集提供了许多操作,如加法、减法、乘法、比较和浮点运算,这些操作可以在128位的寄存器上同时作用于16位、32位、64位的数据元素。Neon寄存器是128位的,可以被视为1个128位、2个64位、4个32位、8个16位或者16个8位的数据元素。Neon汇编通常也被用于优化性能,如视频编解码、图像处理和音频处理等。由于Neon指令集提供了非常多的操作和灵活性,因此需要开发者有深入的理解和经验才能有效地使用。
三、相关工作
由于网上许多neon汇编优化工作都是和C语言相比,虽然具有一定参考意义,但本身C语言做的功能实现限制较多也比较简单,这篇博客更偏向于直接和OpenCV进行比较,毕竟在性能优化方面,OpenCV已经做的非常不错,内部引入了OpenMP,OpenCL,NEON等技术,也考虑到了很多细节场景。可能读者们会感到诧异,明明OpenCV都引入了NEON,做啥还要专门再写一套NEON。
其实不然,这是由于受用群体不同,才有了这篇博客,如何理解?正是因为OpenCV是广受大众喜爱的一款图像处理开源软件,所以它内部考虑了非常多的细节问题,这也就导致如果我们自己使用,适配自己场景的功能并不需要这么完善,假设我们需要落地一套分割算法,源头接入数据流,此时我们发现,由于落地时很多摄像头拉取的画面比例支持4:3或者16:9,刚好可以投机取巧,调用128位的寄存器进行处理(一次16个像素)。
四、实现
我们先看下一张BGR图像内部是如何排列的:
当我们需要对图像像素值进行操作时,理论上我们只需要知道首指针,利用首指针进行移位和赋值,就可以对像素值进行操作。
那么接下来,我们先熟悉下几个会经常用到的neon函数以及数据类型:
| 数据操作 | 说明 |
|---|---|
| vld1_u8 | 从内存中读取8*8位数据到寄存器 |
| vld1q_u8 | 从内存中读取16*8位数据到寄存器 |
| vld3q_u8 | 从内存中读取3个16*8位数据到寄存器中 |
| vst3q_u8 | 将三个128位寄存器的数据写到内存中 |
| vld4_u8 | 从内存中读取4个8*8位数据到寄存器中 |
| vmull_u8 | 执行两个8*8位无符号整数的乘法操作 |
| vshrn_n_u16 | 16位无符号整数右移指定的位数 |
| vst1_u8 | 将128位寄存器中的8位无符号整数元素存储到内存中 |
| vshrq_n_s16 | 16位整数右移指定的位数 |
4.1 BGR转RGB
我们先丢出BGR转RGB操作的neon intrinsic代码,如下:
void bgr_to_rgb(uint8_t *bgr, uint8_t *rgb, int width, int height) { // Ensure BGR and BGR buffers are 16-byte aligned for NEON uint8_t *bgr_aligned = (uint8_t *)(((uintptr_t)bgr + 15) & ~15); uint8_t *rgb_aligned = (uint8_t *)(((uintptr_t)rgb + 15) & ~15); for (int q = 0; q < height * width / 16; q++) { // Calculate the index for the current pixel int index = q * 16 * 3; // Load 16 BGR pixels into three vectors. uint8x16x3_t bgr_vector = vld3q_u8(bgr_aligned + index); // Shuffle the bytes to convert from BGR to BGR. uint8x16_t b = bgr_vector.val[2]; // Blue uint8x16_t g = bgr_vector.val[1]; // Green uint8x16_t r = bgr_vector.val[0]; // Red // Combine the shuffled bytes into a single vector. uint8x16x3_t rgb_vector = {b, g, r}; // Store the result. vst3q_u8(rgb_aligned + index, rgb_vector); } } 4.2 BGR转GRAY的neon操作
接着,我们给出BGR转GRAY的neon intrinsic操作代码,如下:
void bgr_to_gray(uint8_t *bgr, uint8_t *gray, int width, int height) { // 读取8字节的预设值到64位寄存器 // 将一个标量扩展城向量 8 bit * 8 uint8x8_t rfac = vdup_n_u8(77); // 转换权值 R uint8x8_t gfac = vdup_n_u8(151); // 转换权值 G uint8x8_t bfac = vdup_n_u8(28); // 转换权值 B size_t n = width * height / 16; // 每次处理16个像素 for (size_t i = 0; i < n; i++) { uint16x8_t temp; // uint8x8 表示将64bit寄存器 分成 8 个 8bit uint8x8x4_t bgr_vector = vld4_u8(bgr); // 一次读取4个unit8x8到4个64位寄存器 temp = vmull_u8(bgr_vector.val[0], rfac); // temp=bgr.val[0]*rfac temp = vmlal_u8(temp, bgr_vector.val[1], gfac); // temp=temp+bgr.val[1]*gfac temp = vmlal_u8(temp, bgr_vector.val[2], bfac); // temp=temp+bgr.val[2]*bfac uint8x8_t result = vshrn_n_u16(temp, 8); // vshrn_n_u16 会在temp做右移8 位的同时将2字节无符号型转成1字节无符号型 vst1_u8(gray, result); // 转存运算结果到dest // 处理第二个8像素 temp = vmull_u8(bgr_vector.val[3], rfac); // temp=bgr.val[3]*rfac temp = vmlal_u8(temp, bgr_vector.val[4], gfac); // temp=temp+bgr.val[4]*gfac temp = vmlal_u8(temp, bgr_vector.val[5], bfac); // temp=temp+bgr.val[5]*bfac result = vshrn_n_u16(temp, 8); // vshrn_n_u16 会在temp做右移8 位的同时将2字节无符号型转成1字节无符号型 vst1_u8(gray + 8, result); // 转存运算结果到dest bgr += 16 * 3; gray += 16; } } 五、测试
上述代码相对来说比较简单,我们直接在板端上测试效果,测试机器位4核A76+4核A55的ARM板,测试对应的OpenCV版本为4.5.5.
5.1 先看下BGR2RGB的测试对比耗时:
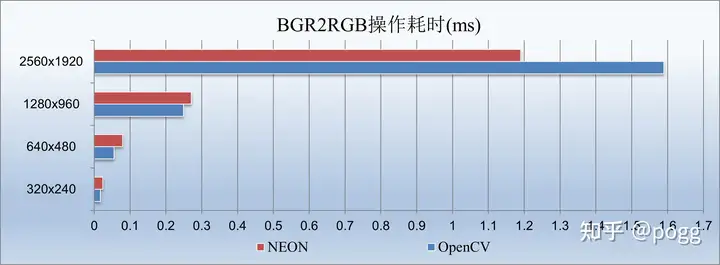
从上述图表不难看出,在图像尺度较大的时候,利用neon的128位寄存器进行数据搬运,是非常有优势的,然而当图像尺寸到了1280以下,优势已被OpenCV反超,这时候我们可以看下CPU内核的资源占用。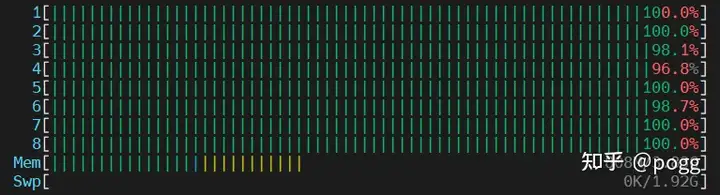
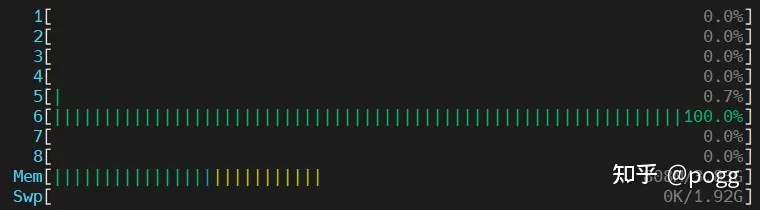
OpenCV基本已将8颗CPU核全部占满,反观NEON操作全程只使用到一颗CPU核。
5.2 再看下BGR2GRAY的测试对比耗时: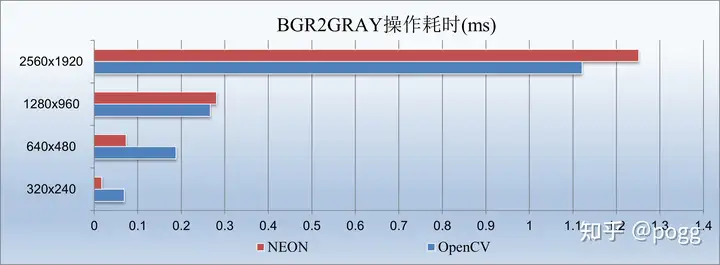
我们看到了与第一小节几乎相反的情况,从1280以下的尺寸开始,neon几乎吊打了OpenCV,我们看下转灰度图和转RGB的区别。由于转灰度图是,通常使用以下公式来计算每个像素的灰度值:
gray = 0.299 * R + 0.587 * G + 0.114 * B 这里的R、G、B分别代表红色、绿色和蓝色通道的像素值,范围通常是0到255。0.299、0.587和0.114是色彩转换系数,它们分别代表了人眼对红、绿、蓝颜色的敏感度。这些系数加起来等于1,以确保转换后的灰度图像的亮度与原始彩色图像相似。
因此,在转换时,资源消耗已不是在数据搬运上面,而且用于一系列的乘加操作,在尺寸越大时,进行乘加操作的次数增加,单核的资源越容易到达瓶颈。
同样看下内核占用的情况: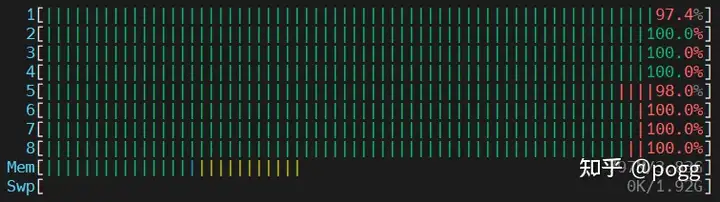
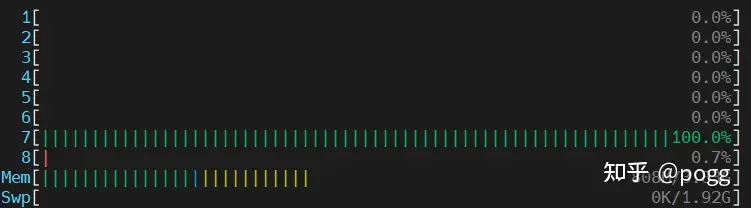
OpenCV依旧把所有的CPU核利用得满满当当。
六、像素拆分再加速
NEON只能打到这里了吗?那不一定,我们做一些拆分措施,继续压榨下单核的资源。
如上,我们将一张图拆分成两个Block同时进行处理,此时for循环内只需处理一半的数据流,代码如下:
void bgr_to_rgb_half(uint8_t *bgr, uint8_t *rgb, int width, int height) { // Ensure BGR and BGR buffers are 16-byte aligned for NEON uint8_t *bgr_aligned = (uint8_t *)(((uintptr_t)bgr + 15) & ~15); uint8_t *rgb_aligned = (uint8_t *)(((uintptr_t)rgb + 15) & ~15); int gap = height * width * 3 / 2; for (int q = 0; q < height * width / 16 / 2; q++) { // Calculate the index for the current pixel int index = q * 16 * 3; // Load 16 BGR pixels into three vectors. uint8x16x3_t bgr_vector_upper = vld3q_u8(bgr_aligned + index); // Shuffle the bytes to convert from BGR to BGR. uint8x16_t b_upper = bgr_vector_upper.val[2]; // Blue uint8x16_t g_upper = bgr_vector_upper.val[1]; // Green uint8x16_t r_upper = bgr_vector_upper.val[0]; // Red // Combine the shuffled bytes into a single vector. uint8x16x3_t rgb_vector_upper = {b_upper, g_upper, r_upper}; // Store the result. vst3q_u8(rgb_aligned + index, rgb_vector_upper); /* upper block end*/ // Load 16 BGR pixels into three vectors. uint8x16x3_t bgr_vector_lower = vld3q_u8(bgr_aligned + gap + index); // Shuffle the bytes to convert from BGR to BGR. uint8x16_t b_lower = bgr_vector_lower.val[2]; // Blue uint8x16_t g_lower = bgr_vector_lower.val[1]; // Green uint8x16_t r_lower = bgr_vector_lower.val[0]; // Red // Combine the shuffled bytes into a single vector. uint8x16x3_t rgb_vector_lower = {b_lower, g_lower, r_lower}; // Store the result. vst3q_u8(rgb_aligned + gap + index, rgb_vector_lower); } } 这个时候,我们可以简单对比下优化后的耗时对比: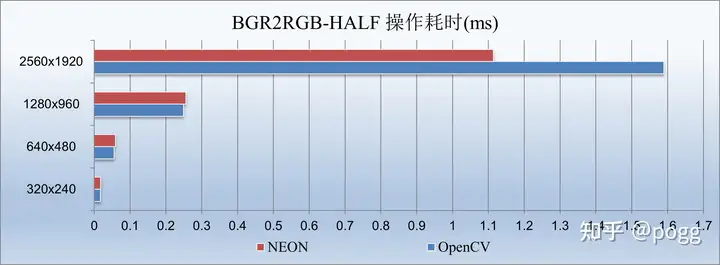
差距再进一步缩小,甚至是无限逼近了8核并行的OpenCV,320x240图像分辨率是0.017ms(cv)和0.018ms(neon),640x480图像分辨率是 0.055ms(cv)和0.059ms(neon),由此可以看出two block的压缩策略是有效果的。
如果将two block的策略继续增加到four block呢?很遗憾,单核资源已然到达瓶颈,出现了反优化的效果,但还是有其它策略方向,比如多核并行,再拉出一个CPU,凑双跑并行加速,当然,回归到主题,文章只是想验证单核NEON效果。
以下是NEON跑出来的效果:

与OpenCV处理的结果基本一致。
七、参考:
[1] https://developer.arm.com/documentation/102467/0201/Example—RGB-deinterleaving%3Flang%3Den