使用Llama 私有化模型检索文档回答问题
部署 Llama 模型
Llama 属于文字生成模型,可以用于聊天。使用 Ollama 部署 Llama 模型,先安装 Ollama
sudo curl -L https://ollama.com/download/ollama-linux-amd64 -o /usr/bin/ollama sudo chmod +x /usr/bin/ollama sudo useradd -r -s /bin/false -m -d /usr/share/ollama ollama配置 Ollama 服务 /etc/systemd/system/ollama.service
[Unit] Description=Ollama Service After=network-online.target [Service] ExecStart=/usr/bin/ollama serve User=ollama Group=ollama Restart=always RestartSec=3 [Install] WantedBy=default.target修改 Ollama 服务监听的地址和端口号:
在[Service]部分添加一行:Environment="OLLAMA_HOST=0.0.0.0:您的端口号"。注意替换“您的端口号”为实际的端口号,默认端口号是 11434
启动 Olama 服务
sudo systemctl daemon-reload sudo systemctl enable ollama使用 Ollama 拉取 Llama 模型
ollama run llama3.1这样 Llama 模型成功启动,可以在终端和 Llama 语言模型对话了
部署 nomic-embed-text 文本嵌入模型
nomic-embed-text 模型可以将文字转为数字,含义相似词汇分值也接近。可以将他们存入向量数据库,根据相似度检索拿出相关文档。
有了 Ollama 模型,部署 文本嵌入模型就一条命令
ollama pull nomic-embed-text测试 Llama 模型
先将我们上个文章 使用 openai 和 langchain 调用自定义工具完成提问需求 里的那个使用 langchain 框架,openai 作为模型,写得 由大模型决定调用的工具(计算器),拿到工具处理结果,回答用户提问的 程序,我们将它的模型从 openai 改成 我们刚刚私有化部署的 Llama 模型。
改动地方不多,将
chat_model = ChatOpenAI()改成
from langchain_community.llms import Ollama chat_model = Ollama(base_url='http://localhost:11434', model="llama3.1")这样 使用 openai 和 langchain 调用自定义工具完成提问需求 完整代码的 Llama实现如下:
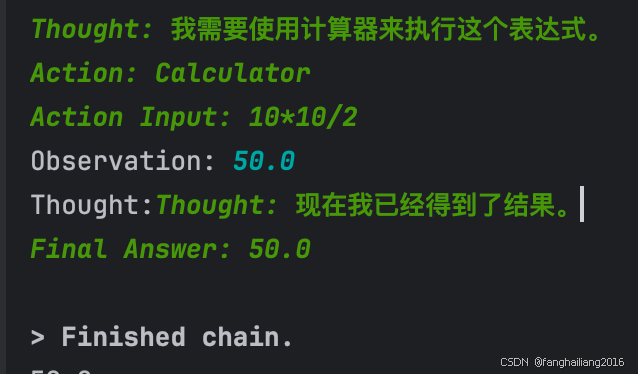
from langchain_community.llms import Ollama from langchain.agents import AgentType, initialize_agent from langchain.tools.base import BaseTool # 定义一个自定义工具类 class Calculator(BaseTool): name = "Calculator" description = "运行加减乘除运算的表达式" def _run(self, query: str): """Use the tool.""" # 在这里实现您的自定义函数逻辑 result = self.custom_function(query) return result async def _arun(self, query: str): """Use the tool asynchronously.""" raise NotImplementedError("This tool does not support async") def custom_function(self, expression: str): """Your custom function logic goes here.""" # 示例:将输入文本转换为大写 return eval(expression) # 创建工具实例 calculator = Calculator() tools = [calculator] chat_model = Ollama(base_url='http://localhost:11434', model="llama3.1") # 初始化代理 agent = initialize_agent(tools, chat_model, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True) response = agent.run("计算 10*10/2") print(response)看不懂可参考我的上一篇文章 使用 openai 和 langchain 调用自定义工具完成提问需求
llama3.1 模型的运行结果如下:
使用向量数据库存储私有知识库
在这个示例中,假设我们企业的私有知识存储在 https://developers.mini1.cn/wiki/luawh.html 这个链接对应的文档中,我们希望大模型能根据这个文档的内容,回答 “LUA 的宿主语言是什么?” 这个问题。事实上,我们企业的私有知识库非常庞大,将他们全部传入大模型,让他根据这些内容回答你的问题不太现实,于是需要一个向量数据库,企业的私有知识库存在向量数据库中,当需要回答问题时,先从私有知识库中,根据提问的关键词,找到分值最接近的相关文档,将这些相关文档传入大模型,让大模型基于这些回答你的问题。
也就是说,使用向量数据库是为了减少大模型阅读不必要的文字。在这里,使用上面私有化部署的 nomic-embed-text 这个模型完成文字到向量的转换,向量数据库使用 faiss,需要首先安装依赖包
pip install faiss-cpu从网页加载文档
from langchain_community.document_loaders import WebBaseLoader loader = WebBaseLoader("https://developers.mini1.cn/wiki/luawh.html") data = loader.load()对文档切割成块
from langchain.text_splitter import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0) splits = text_splitter.split_documents(data)把切成块的文档,调用文本嵌入模型,拿到他的分值(向量),存入 fsiss 向量数据库中。
from langchain.embeddings.ollama import OllamaEmbeddings embedding = OllamaEmbeddings(base_url='http://' + host + ':11434', model="nomic-embed-text") from langchain_community.vectorstores import FAISS vectordb = FAISS.from_documents(documents=splits, embedding=embedding)构造 RetrievalQA 链
from langchain_community.chat_models import ChatOllama from langchain.retrievers.multi_query import MultiQueryRetriever from langchain.chains import RetrievalQA # RetrievalQA链 llm = ChatOllama(base_url='http://' + host + ':11434', model="llama3.1") retriever_from_llm = MultiQueryRetriever.from_llm(retriever=vectordb.as_retriever(), llm=llm) # 实例化一个RetrievalQA链 qa_chain = RetrievalQA.from_chain_type(llm,retriever=retriever_from_llm)使用这个 QA 链回答问题
question = "LUA 的宿主语言是什么?" result = qa_chain({"query": question}) print(result)到此结束,运行结果如下:

总结:今天很开心,将大模型 Llama 和 nomic-embed-text 私有化部署,在纯内网的环境中实现了 RGA 流程,而不是浪费钱的去访问外网,关键是,体验效果还不错,机器配置要求也不是很高,gpu 一般就行。
MyPostMan: MyPostMan 是一款类似 PostMan 的接口请求软件,按照 项目(微服务)、目录来管理我们的接口,基于迭代来管理我们的接口文档,文档可以导出和通过 url 实时分享,按照迭代编写自动化测试用例,在不同环境中均可运行这些用例。