nodemanage_文章的主旨是什么?
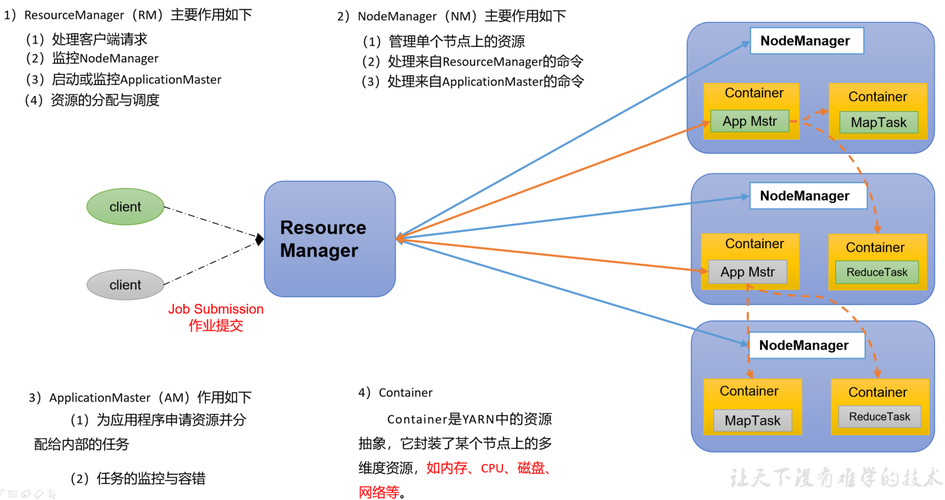
NodeManager的角色与功能
 (图片来源网络,侵删)
(图片来源网络,侵删)基本职能
NodeManager(NM)在Hadoop集群中扮演着至关重要的角色,它位于每个计算节点上,负责管理该节点的运算资源,具体而言,NM需要与ResourceManager(RM)进行持续通信,以保持对集群资源状态的同步,它同时负责监控Container的资源使用情况和节点的健康状态,以及管理Container的生命周期和日志文件。
职责详解
与ResourceManager同步:NM定期与RM进行通信,报告其管理的节点状态,包括资源使用情况和运行状况,确保RM能够准确掌握整个集群的资源分配情况。
节点健康追踪:NM监控其所在节点的硬件和操作系统健康状况,如内存使用率、磁盘空间和网络状况,及时发现并上报可能的问题。
Container管理:NM负责启动、监控和终止Container,每一个Container对应于一个特定应用的一个执行实例,NM确保每个Container获得所需的资源,并在整个生命周期内正常运作。
分布式缓存管理:NM处理应用程序所需的外部文件资源,如JAR包和库文件,确保这些资源在各计算节点间的有效缓存和访问。
 (图片来源网络,侵删)
(图片来源网络,侵删)日志管理:NM负责管理Container生成的日志文件,包括日志的存储和访问控制,为调试和问题排查提供必要的信息支持。
NodeManager配置与管理
配置内存
NodeManager的内存配置是优化YARN集群性能的关键步骤之一,合理的内存配置可以确保Container平稳运行,避免由于资源短缺导致的应用失败,内存配置通常涉及对YARN的基本配置参数进行调整,例如yarn.nodemanager.resource.memorymb设定了NM可管理的总内存量,而yarn.nodemanager.vmempmemratio则控制虚拟内存与物理内存的使用比例。
容器管理
NodeManager的容器管理策略直接影响到集群的运算效率和稳定性,通过调整容器的大小和数量,管理员可以平衡应用的性能和资源利用率,增加容器的数量可以提高集群的处理能力,但也可能导致更频繁的资源调度和潜在的资源竞争问题。
健康监控
 (图片来源网络,侵删)
(图片来源网络,侵删)为了维持集群的稳定性,NodeManager必须具备有效的健康监控机制,这包括对硬件故障的及时响应和自动化的恢复策略,通过配置合适的监控参数和设置预警系统,管理员可以快速定位问题并进行干预,减少系统停机时间。
实际应用操作
启动过程
NodeManager的启动通常通过运行Hadoop配置文件所在的脚本进行,在hadoop2.7.2版本中,可以通过执行yarndaemon.sh start nodemanager命令来启动NM服务,这一过程应在所有计算节点上重复执行,以确保每个节点上的NM都能正确启动并加入到集群中。
配置示例
为了帮助理解具体的配置方法,以下是一个NodeManager的内存配置示例,展示如何设定NM的内存资源限制:
yarn.nodemanager.resource.memorymb 8192 Define the total memory that can be allocated for containers by the NM. yarn.nodemanager.vmempmemratio 2.1 Controls the relative amount of physical and virtual memory usage.
这个配置允许NodeManager管理最多8192MB的物理内存,并设置虚拟内存与物理内存的使用比率为2.1,这意味着虚拟内存的使用上限将是物理内存的2.1倍,有助于处理内存溢出的情况。
优化和维护
性能优化
NodeManager的性能可以通过多种方式进行优化,合理设置容器大小和数目,根据应用程序的实际需求调整内存和CPU的分配,可以显著提升应用运行的效率和响应速度,监控工具的使用也是优化的一部分,它们可以帮助管理员实时了解NodeManager的运行状态,及时调整配置以适应不断变化的工作负载。
常见问题维护
NodeManager在运行过程中可能会遇到各种问题,如资源分配失败、Container启动失败等,这些问题通常可以通过查看NM的日志文件来诊断,管理员应定期检查这些日志,并根据日志中的错误信息进行相应的配置调整或硬件检查。
相关问答FAQs
NodeManager不启动怎么办?
问题解答
如果NodeManager无法启动,首先应检查Hadoop安装目录中的日志文件,特别是NodeManager的日志,以确定失败的原因,常见的问题包括配置错误、端口冲突或权限问题,确认所有配置文件的设置正确无误后,尝试重新启动NodeManager服务,并确保所有必要的端口未被其他服务占用。
如何监控NodeManager的性能?
问题解答
监控NodeManager的性能可以通过多种工具和策略实现,Hadoop生态系统提供了Web界面,如ResourceManager的Web UI,可以显示NodeManager的状态和运行中的应用信息,还可以利用第三方监控工具,如Ganglia或Prometheus,这些工具可以提供更详细的资源使用数据和性能指标,帮助管理员更好地理解和优化集群性能。