如何在MySQL数据库中实现编码排序?
COLLATE utf8mb4_unicode_ci来进行正确的编码排序。在MySQL数据库中,编码排序是一个关键的操作,它涉及到数据的存储、检索和处理等多个方面,本文将详细解析MySQL数据库中的编码排序机制,帮助用户更好地理解和应用这一功能。
 (图片来源网络,侵删)
(图片来源网络,侵删)MySQL数据库中的编码与排序规则
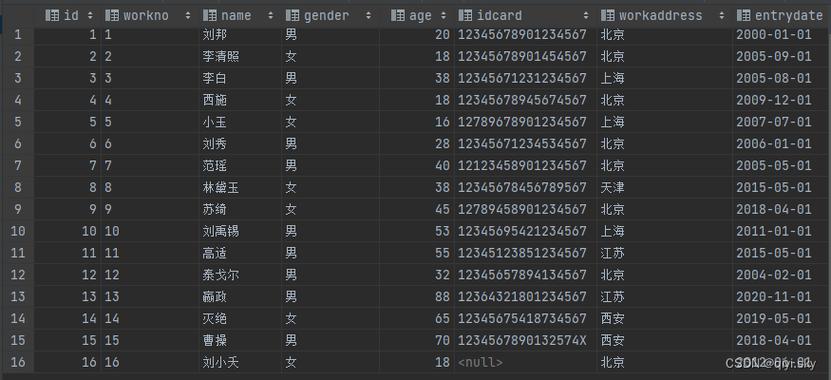
在MySQL数据库中,字符编码(Character Set)和排序规则(Collation)是两个基本概念,字符编码决定了数据如何被存储和解析,而排序规则则影响到数据的比较和排序,使用utf8mb4_unicode_ci可以基于标准的Unicode进行排序和比较,适用于多语言环境,能够实现各种语言之间的精确排序。
查看数据库及数据表的编码和排序规则
查看数据库编码:使用SHOW CREATE DATABASE 数据库名;命令可以查看指定数据库的编码设置。
查看数据表编码:通过SHOW CREATE TABLE 表名;命令,可以查看特定表的编码信息。
查看字段排序规则:使用SHOW FULL COLUMNS FROM 表名;可以查看数据表中各个字段的排序规则。
这些命令对于确保数据库设置正确,以及在出现问题时进行故障排除非常有用。
 (图片来源网络,侵删)
(图片来源网络,侵删)设置数据库的编码和排序规则
MySQL允许在不同的级别设定字符编码:服务器级别、数据库级别、表级别和列级别,如果在创建数据库时未明确指定编码,则会使用服务器级别的默认设置,用户可以在创建数据库时通过CREATE DATABASE test2 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;这样的方式来指定所需的编码和排序规则。
选择合适的编码和排序规则非常重要,因为它们将影响数据库存储数据的方式以及数据间的比较和排序方式。utf8mb4_general_ci虽然在比较和排序时速度较快,但在遇到特殊语言或字符时可能会出现错误。
准确性与性能考量
选择编码和排序规则时,需要从准确性和性能两方面进行权衡:
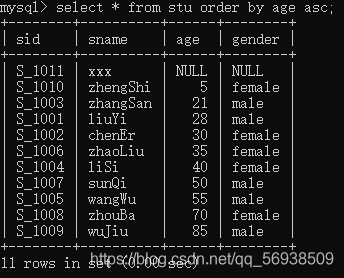
准确性:utf8mb4_unicode_ci基于Unicode标准进行排序和比较,适合需要高精度多语言支持的场景。
性能:utf8mb4_general_ci在比较和排序时更快,适合性能优先的应用场合。
 (图片来源网络,侵删)
(图片来源网络,侵删)相关实操建议
在操作MySQL数据库时,合理设置和管理编码及排序规则是保证数据完整性和查询效率的关键,以下是一些实用建议:
在设计数据库结构时,根据业务需求和预期的数据类型选择合适的编码和排序规则。
定期检查和审视数据库的编码及排序规则,确保它们仍符合当前的需求。
当出现排序或显示错误时,应首先检查相关字段的编码和排序规则设置。
MySQL数据库的编码排序是一个细节丰富且重要的领域,正确的设置不仅能保证数据的准确性,还能优化数据库的性能,理解并合理运用这些设置,将有助于提升数据库的整体运行效率和数据处理能力。
FAQs
Q1: 修改已有数据库或表的编码和排序规则有哪些方法?
修改数据库:可以使用ALTER DATABASE 数据库名 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;来更改整个数据库的编码和排序规则。
修改数据表:使用ALTER TABLE 表名 CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;可以改变表的编码和排序规则,这会自动转换已有数据至新的编码。
Q2: 如果数据库出现乱码,可能是哪些原因造成的?
编码不匹配:输入或输出的数据编码与数据库或表设置的编码不一致。
错误的排序规则:使用的排序规则无法正确处理某些特殊字符,导致乱码现象。
数据传输问题:在数据传输过程中编码设置不当也可能导致乱码。
解决这些问题通常需要调整相关的编码设置或确保数据传输过程的编码一致性。