如何利用MySQL进行列数据库的统计操作?
在各个业务和科研领域,数据库的作用愈发重要,MySQL作为广泛应用在全球的开源关系型数据库管理系统,提供了强大的数据存储、管理与分析功能,本文将深入探讨MySQL中如何进行列数据的统计,包括各种命令和函数的使用,以帮助用户更好地理解和操作MySQL数据库,优化数据查询和管理过程。
 (图片来源网络,侵删)
(图片来源网络,侵删)统计列数据的基本方法
确定表中列数
在MySQL中,INFORMATION_SCHEMA.COLUMNS是一个系统表,它存储了数据库中所有表的列信息,通过简单的查询,即可得到任意表的列数,使用以下SQL命令,可以统计出指定表的列数:
SELECT COUNT(*) FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME='表名';
这为了解表结构提供了极大的便利,尤其是在大型数据库操作中,快速获得列数有助于数据管理和查询优化。
统计函数的应用
MySQL提供了一系列的统计函数,这些函数可以在SELECT子句中使用,返回数据集的结果,常用的统计函数包括COUNT(),SUM(),AVG(),MIN(),MAX()等,要统计一列中不同值的数量,可以使用COUNT(DISTINCT column_name)函数:
SELECT COUNT(DISTINCT column_name) FROM table_name;
这个函数对于数据分析非常有用,可以迅速得到某列中不同值的个数,从而对数据分布有一个直观的了解。
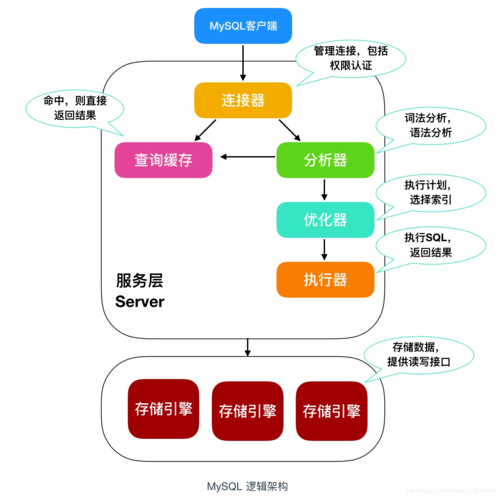 (图片来源网络,侵删)
(图片来源网络,侵删)高级统计技巧
索引和统计信息
MySQL中的统计信息是指数据库通过采样统计出来的关于表和索引的相关信息,比如表的记录数、索引page个数、字段的选择性(Cardinality)等,这些统计信息对于查询优化器生成执行计划至关重要,尽管MySQL支持的统计信息有限,并且其收集方式依赖于存储引擎的不同,但这些信息对于理解数据库性能有着不可或缺的作用,特别是在MySQL 8.0之前的版本中,没有直方图的支持,合理的统计信息更是优化查询的关键。
统计列中不同值的数量
在构建数据看板或进行数据分析时,经常需要统计某一列中不同值的数量,有多种方法可以实现这一需求,例如使用COUNT()配合DISTINCT直接统计或者通过GROUP BY来实现更复杂的数据统计,不同的实现方式在效率和适用场景上有所不同,选择合适的方法可以提高数据处理的效率。
相关数据表的展示
为了更直观地理解上述内容,下面以一个示例表格来展示如何使用这些统计方法:
 (图片来源网络,侵删)
(图片来源网络,侵删)| 统计方法 | SQL示例 | 用途 |
| 表中列数 | SELECT COUNT(*) FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME='订单'; | 获取“订单”表的总列数 |
| 列不同值计数 | SELECT COUNT(DISTINCT 用户ID) FROM 订单; | 计算“订单”表中“用户ID”的不同数量 |
| 使用统计函数 | SELECT COUNT(*), AVG(价格) FROM 订单; | 同时获取订单数量和平均价格 |
| 索引统计信息 | 无直接SQL命令,需通过查询优化器输出或专用工具获取 | 分析索引使用情况,优化查询性能 |
上文归纳及最佳实践
通过对MySQL中列数据的统计方法的探讨,我们可以发现合理的统计操作不仅可以提高数据查询的效率,还能在数据分析等方面发挥重要作用,无论是基本的列数统计,还是复杂的不同值计数,合理运用统计函数和理解索引统计信息都是提升数据库操作技能的关键,随着数据分析需求的增加,掌握这些统计方法变得尤为重要。
FAQs
Q1: 为什么统计函数在数据处理中如此重要?
A1: 统计函数可以提供对数据集的快速汇总信息,如计数、总和、平均值等,这对于数据分析、报告生成和决策支持非常关键,它们能够帮助用户在不查看详细数据的情况下,快速理解数据的总体特征。
Q2: 如何确保统计信息的准确度?
A2: 确保统计信息准确度的一个方法是定期更新统计信息,特别是在大批量数据变更后,选择合适的存储引擎和合理的表设计也可以提高统计信息的有效性和准确性。