如何使用Spark作业高效访问MySQL数据库?
在当今数据驱动的世界中,大数据技术如Spark已成为处理和分析大规模数据集的首选工具,许多情况下,Spark作业需要访问存储在传统关系型数据库(如MySQL)中的数据,本文将探讨Spark作业如何有效访问MySQL数据库的几种技术方案。
 (图片来源网络,侵删)
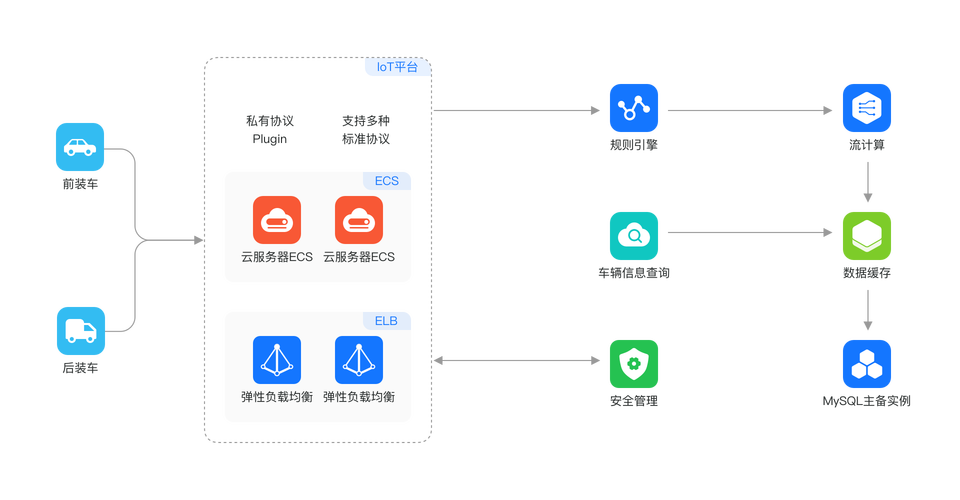
(图片来源网络,侵删)直接连接方式
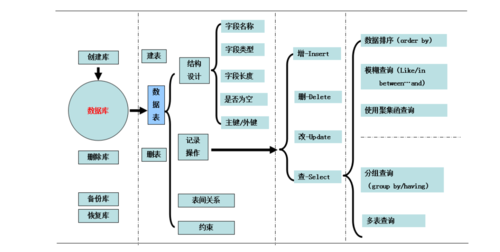
最直接的方法是在Spark作业中直接使用JDBC连接到MySQL数据库,这通常通过Spark的DataFrame API实现,它允许开发者将外部数据库表注册为Spark的临时表,并使用Spark SQL进行查询。
优点:
简单易行,适合小规模数据处理。
不需要额外的中间件支持。
缺点:
性能受限于单个JDBC连接的带宽和延迟。
难以水平扩展,不适合大规模数据处理。
 (图片来源网络,侵删)
(图片来源网络,侵删)SparkMySQL连接器
为了解决直接连接的性能问题,一些开源项目提供了专门优化的SparkMySQL连接器,这些连接器利用Spark的分布式计算能力,可以更高效地从MySQL读取数据。
优点:
提高了数据读取的效率和速度。
更好地支持Spark的分布式计算特性。
缺点:
需要额外安装和维护连接器。
配置和使用相对复杂。
 (图片来源网络,侵删)
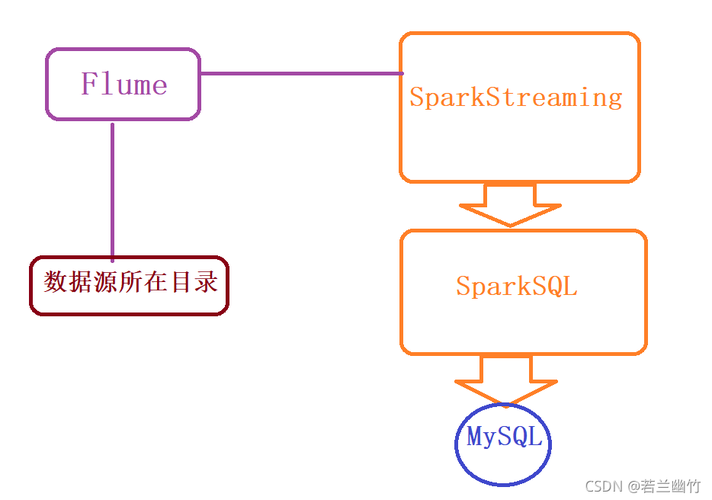
(图片来源网络,侵删)使用中间数据湖
另一种方案是将MySQL数据导出到一个中间数据湖(如HDFS、Amazon S3等),然后由Spark作业从数据湖读取数据。
优点:
数据一旦导出到数据湖,可被多个Spark作业重复使用,提高资源利用率。
适合ETL流程,可以实现数据的清洗和转换。
缺点:
数据导出过程可能耗时且复杂。
需要维护数据湖和MySQL之间的同步机制。
实时数据流方案
对于需要实时或近实时访问MySQL数据的场景,可以使用Apache Kafka等消息队列系统作为缓冲层,Spark Streaming作业可以从Kafka消费MySQL数据库的变更日志,实现近实时的数据访问。
优点:
提供近实时的数据访问能力。
解耦了数据生产和数据消费的过程,提高了系统的可扩展性和健壮性。
缺点:
引入了额外的组件(如Kafka),增加了系统的复杂性。
需要处理消息队列系统的运维问题。
相关问答FAQs
Q1: Spark作业直接连接MySQL时,如何提高查询效率?
A1: 可以通过以下几种方法提高查询效率:
仅查询必要的列,避免SELECT *。
使用分区和索引优化MySQL表。
在Spark作业中对数据进行过滤和聚合,减少数据传输量。
Q2: 使用中间数据湖方案时,如何处理数据的实时更新?
A2: 处理实时更新的策略包括:
定期(如每天一次)将MySQL的新数据导出到数据湖。
使用增量更新策略,只导出自上次导出以来发生变化的数据。
如果业务允许,可以采用事件源方式,将数据变更事件直接发送到数据湖。
方案各有优劣,应根据具体的业务需求、数据规模和现有技术栈来选择最合适的方案。
上一篇:哪个云存储服务最适合您的需求?