如何有效实现MySQL数据库的分布式设计与ClickHouse的分布式表优化?
在当今数据驱动的时代,有效地存储和处理海量数据成为了企业面临的一大挑战,分布式数据库设计因此备受关注,其中MySQL和ClickHouse作为两种流行的数据存储解决方案,它们的分布式设计具有各自的特点和优势,本文将深入探讨MySQL数据库的分布式设计方法以及ClickHouse分布式表的设计细节,帮助读者更好地理解和应用这两种技术。
 (图片来源网络,侵删)
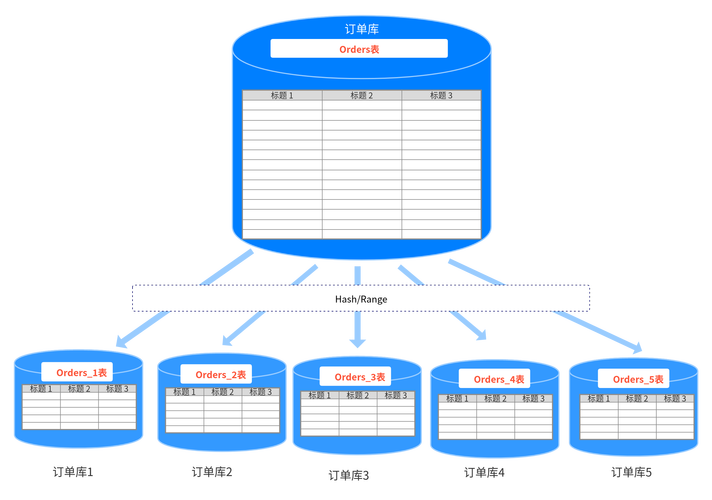
(图片来源网络,侵删)MySQL数据库的分布式设计
MySQL作为一种广泛使用的关系型数据库管理系统,它的分布式设计通常涉及到数据的分片(Sharding)和复制(Replication),通过这些技术,可以在多台服务器之间分散数据和负载,提高数据处理的效率和可靠性。
1、数据分片: 数据分片是将数据集分割成小块,每一块存储在不同的服务器上,这样做可以提高查询速度并简化数据管理,常见的分片策略包括范围分片、哈希分片及目录分片等。
2、数据复制: 数据复制则是指将数据从一台服务器复制到其他服务器,以实现数据的冗余备份和负载均衡,这可以通过主从复制或主主复制等方式实现。
3、高可用性与扩展性: 结合使用分片和复制技术,MySQL的分布式设计不仅提高了数据库的高可用性,也增强了系统的水平扩展性,这对于处理大规模并行事务处理尤为重要。
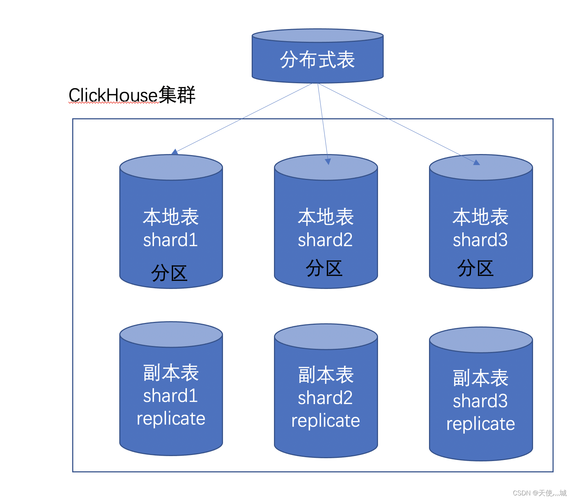
ClickHouse分布式表的设计
ClickHouse作为一个用于在线分析处理(OLAP)的列式数据库管理系统,其分布式表设计主要依赖于Distributed表引擎,该引擎提供了一种在所有分片(本地表)上建立视图进行分布式查询的能力。
 (图片来源网络,侵删)
(图片来源网络,侵删)1、Distributed表引擎: Distributed表引擎是ClickHouse中一种特殊的表引擎,它本身不存储任何数据,而是作为分布式表的一层透明代理,通过定义分布式表,用户可以在多个节点上执行查询而无需关心数据的实际物理位置。
2、集群搭建与维护: ClickHouse的分布式集群搭建是一个彻底手动的过程,这虽然增加了操作复杂性,但也提供了更多的灵活性和定制化能力,用户可以根据自己的需求调整集群的配置和维护策略。
3、数据分布策略: 在ClickHouse中,数据的分布可以通过不同的策略来实现,例如使用rand()函数随机分布,或者其他基于某些键的值来分布数据,这有助于均衡各节点的负载并优化查询性能。
对比与选择建议
当比较MySQL和ClickHouse的分布式设计时,可以看出两者各有千秋,MySQL的分布式设计侧重于通过分片和复制提高事务处理的性能和可靠性,适合需要高并发写入和强一致性保障的应用,而ClickHouse的分布式设计则更专注于高效的数据分析查询,适用于大数据量的在线分析处理场景。
根据具体的业务需求选择合适的工具非常关键,如果业务重点是事务处理和实时交互,MySQL可能是更好的选择;如果业务需求倾向于大数据分析及报告生成,ClickHouse的分布式解决方案将更为合适。
无论是选择MySQL还是ClickHouse,理解其分布式设计的基本原理和适用场景都是确保数据存储解决方案成功实施的关键,通过合理配置和优化,这两种数据库系统都能提供强大的支持,帮助企业有效管理和分析日益增长的数据。
 (图片来源网络,侵删)
(图片来源网络,侵删)FAQs
什么是分布式数据库?
分布式数据库是一种数据库系统,其数据分布在网络中的多个点上,这种系统提供了不同透明度级别的分布式数据管理,分布式数据库可以提供更高的查询效率、更大的存储容量以及更强的故障恢复能力。
如何确保分布式数据库系统的高可用性?
确保高可用性通常包括数据复制、故障转移机制、及时的备份与恢复策略等措施,在MySQL中可能采用主从复制或环形复制来同步数据到多个副本;而在ClickHouse中,则可能依赖其分布式表的自我修复特性和副本之间的数据同步来保证服务的持续可用。