如何在MySQL中查询指定一周内的数据记录?
WEEK()函数结合YEAR()函数来筛选特定周和年份的记录。要查询第W周的数据,可以使用以下SQL语句:,,``sql,SELECT * FROM your_table,WHERE YEAR(your_date_column) = 2022 AND WEEK(your_date_column, 1) = W;,`,,your_table是数据表名,your_date_column是日期列名,2022是年份,W是目标周数。注意WEEK()`函数的第二个参数决定了周的起始日,1表示周从周日开始。在MySQL数据库中,获取某一周的数据是日常数据处理和分析的常见需求,了解如何精确地查询一定时间范围内的数据,对于数据分析、报告生成及数据维护均具有重要意义,本文旨在通过详尽的解析和示例,帮助读者掌握在MySQL中进行周数据查询的有效方法。
 (图片来源网络,侵删)
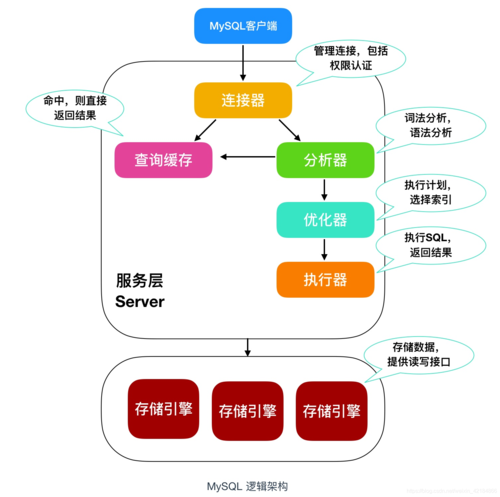
(图片来源网络,侵删)基本查询结构
在MySQL中进行日期查询时,可以使用SELECT语句结合日期函数来实现,基本的查询结构为SELECT ... FROM ... WHERE ...。WHERE子句是实现日期筛选的关键部分。
使用DATE_SUB与CURDATE()
一个简单而有效的方法是结合使用DATE_SUB()函数和CURDATE()函数,要查询近一周的数据,可以使用以下SQL语句:
SELECT * FROM 表名称 WHERE DATE_SUB(CURDATE(), INTERVAL 6 DAY) <= date(表内时间字段);
这里,DATE_SUB(CURDATE(), INTERVAL 6 DAY)用于获取从当前日期往前推6天的日期,<= date(表内时间字段)则确保选取的日期范围包括今天及之前6天的所有日期,即过去一周的数据。
利用WEEK函数
另一个常见的方法是使用WEEK()函数,此函数可以提取日期的周信息,要查询当前周的数据,可以采用如下SQL语句:
 (图片来源网络,侵删)
(图片来源网络,侵删)SELECT * FROM table_name WHERE WEEK(date_column) = WEEK(CURDATE());
在这个查询中,WEEK(date_column)会获取date_column列中每一行的日期所在的周数,并与当前日期的周数WEEK(CURDATE())进行比较,这样,只有与当前日期位于同一周的行才会被选中。
跨年及周起始日问题
处理周数据时需要注意的一个特殊情形是跨年及周起始日的问题,不同国家和地区对于一周的开始日(星期一或星期日)以及跨年周的处理方式可能不同,这需要根据具体的业务需求来调整查询逻辑,某些情况下可能需要人为定义跨年周的归属规则,以避免数据的重复计算或遗漏。
高级查询优化
对于大型数据库应用,提高查询效率是至关重要的,可以通过建立合适的索引来优化周数据的查询速度,在时间字段上创建索引可以显著提高基于时间范围的查询操作的速度。
合理使用查询缓存、分区表等高级功能也可以进一步提升查询性能,尤其是在处理海量数据时。
MySQL提供了丰富的函数和工具来支持获取某一周的数据,通过合理运用DATE_SUB()、WEEK()等函数,并注意周数据查询中的特殊问题如跨年处理和周起始日设置,可以实现高效准确的周数据抽取,针对实际的业务需求和数据库特性进行相应的查询优化,也是确保数据准确、提升查询效率的关键步骤。
 (图片来源网络,侵删)
(图片来源网络,侵删)相关问答FAQs
如何确保查询结果的准确性?
确保查询准确性的关键是正确使用MySQL的日期和时间函数,特别是理解它们在不同语境下的行为,了解WEEK()函数如何处理跨年数据和不同地区的周起始日差异,充分测试查询条件在边缘情况下的表现也同样重要。
如何优化这类查询的性能?
优化查询性能可以从几个方面考虑:一是为时间字段创建索引,以加速时间范围的查询;二是合理设计数据库表结构,可能的话使用分区表来管理大规模时间序列数据;三是适当配置MySQL的查询缓存机制,减少重复查询的开销,定期审查和优化SQL查询本身,避免不必要的负载。