如何利用随机森林回归在MySQL中随机获取多条数据?
创始人
2024-10-17 15:36:36
在MySQL数据库中,要随机获取多条记录,可以使用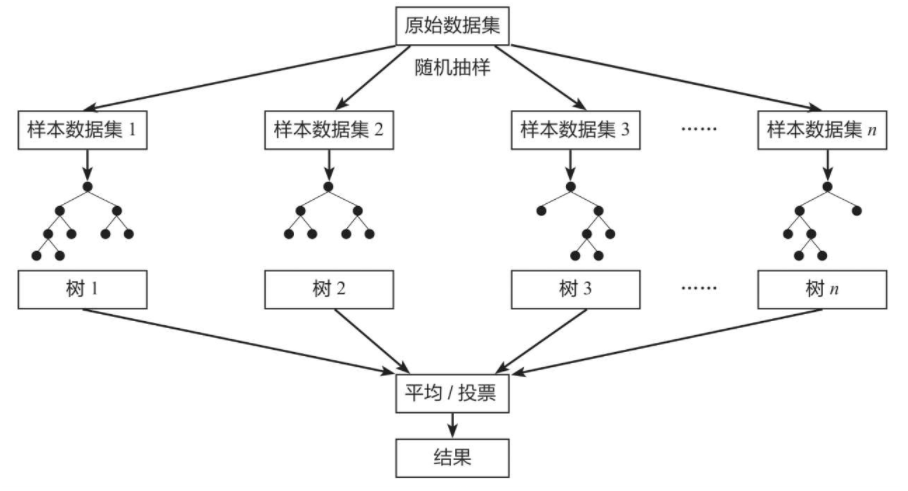 (图片来源网络,侵删)
(图片来源网络,侵删)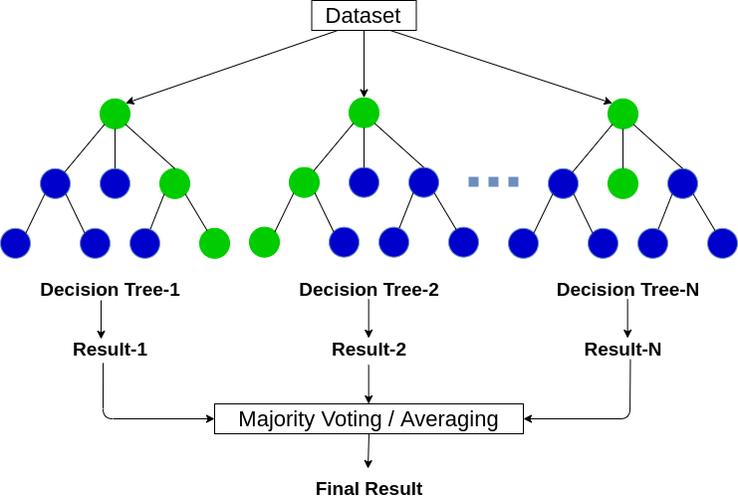 (图片来源网络,侵删)
(图片来源网络,侵删)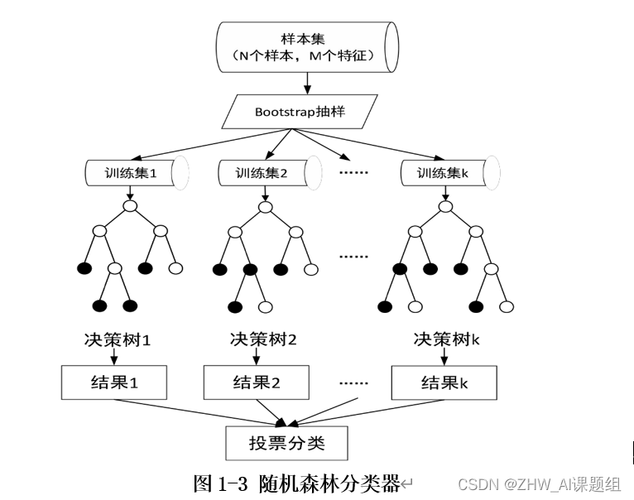 (图片来源网络,侵删)
(图片来源网络,侵删)
ORDER BY RAND()函数配合LIMIT子句。从表中随机选择10条记录,可以使用以下查询:,,``,SELECT * FROM table_name ORDER BY RAND() LIMIT 10;,`,,这种方法适用于较小的数据集,因为RAND()`函数会对每一行进行计算,可能影响性能。对于大数据集,可以考虑其他优化方法。1、随机获取数据库记录的方法
(图片来源网络,侵删)在MySQL中,使用ORDER BY RAND()可以实现记录的随机排序。SELECT * FROM table_name ORDER BY RAND() LIMIT 1;可以从表中随机选择一条记录,尽管这种方法简单直接,但在处理大量数据时效率较低,因为需要对整个结果集进行排序。
2、随机森林回归的原理
随机森林回归是一种集成学习方法,它通过构建多个决策树来提高预测的准确性和稳定性,每个决策树在训练时使用随机的数据集和特征子集,从而减少模型间的相关性并提高整体性能,这种算法特别适合处理高维数据和复杂的非线性关系。
3、随机森林回归的实现
利用Python的Scikitlearn库可以方便地实现随机森林回归,该库提供了RandomForestRegressor类,用户可以通过调整类参数如树的数量、最大深度等来优化模型,实例化后,使用fit方法训练模型,并通过predict方法进行预测。
4、电商销量预测案例分析
在一个基于电商数据的销量预测项目中,通过随机森林回归模型进行销量预测,项目包括了数据的预处理、特征工程和模型评估等关键步骤,此案例展示了随机森林回归在实际问题中的应用流程和效果,证明了其在处理实际复杂数据集中的有效性。
(图片来源网络,侵删)5、随机森林回归中的参数调优
在随机森林回归模型中,参数的设置对模型的性能有显著影响,常见的调优参数包括树的数量、树的最大深度、最小叶子节点数等,通过交叉验证等技术可以寻找最优的参数组合,以提升模型的预测精度和泛化能力。
(图片来源网络,侵删)
相关内容
热门资讯
华为PuraXMax官宣!大阔...
今天,华为继续进行新品预热,并正式公布了全新的华为Pura X Max大阔折手机。目前,这款新机已经...
大中矿业获得实用新型专利授权:...
证券之星消息,根据天眼查APP数据显示大中矿业(001203)新获得一项实用新型专利授权,专利名为“...
4月17日上线,马斯克的XCh...
当马斯克把“比特币式加密”和“绝不追踪数据”同时写进宣传语,一场关于隐私的信任游戏已经开始。 4月1...
原创 华...
华为新机继续发力,前面预热了华为Pura 90系列,接着预热新一代阔型屏,两大新机均为高端级别,而且...
百信申请服务器安全防护方法及系...
国家知识产权局信息显示,百信信息技术有限公司申请一项名为“一种服务器安全防护方法及系统”的专利,公开...