redis的数据结构与对象
简单动态字符串
文章目录
- 简单动态字符串
- SDS的定义
- SDS的结构
- 图示结构
- SDS字段解析
- SDS的特点
- SDS和字符串的区别
- 常数复杂度获取字符串的长度
- 杜绝缓冲区的溢出
- 减少修改字符串时的内存分配次数
- 二进制安全
- 兼容部分c字符串函数
- 总结
- 链表
- 链表和链表节点的实现
- 链表节点(listNode)
- 链表(list)
- 链表的操作
- 创建链表
- 释放链表
- 添加节点
- 删除节点
- 总结
- 重点回顾
- 字典
- 字典的实现
- 图示结构
- 详细解释
- 哈希算法
- 哈希函数
- 哈希桶索引计算
- **计算桶索引**:
- 图示结构
- 关键点总结
- 解决键冲突
- 解决键冲突的策略
- 哈希冲突的处理流程
- 图示结构
- 关键点总结
- 4. Rehash
- 哈希表的扩展和收缩
- Rehash过程
- 渐进式 Rehash
- 图示结构
- 关键点总结
- Rehash的条件总结
- 1. **哈希表****扩展条件**
- 2. **哈希表****收缩条件**
- 3. **渐进式 Rehash**
- 关键点总结
- 重点回顾
- 跳跃表
- 跳跃表的实现
- 跳跃表节点
- 1. 层(Level)
- 2. 前进指针(Forward Pointers)
- 3. 跨度(Skip)
- 4. 后退指针(Backward Pointers)
- 5. 分值和成员(Score and Member)
- 源码结合
- 1. `zskiplistNode`
- 2. `zskiplist`
- 3. 主要函数
- 跳跃表
- 1. 跳跃表的节点结构
- 2. 跳跃表的结构
- 3. 跳跃表的操作
- 4. 跳跃表的优势
- 整数集合
- 整数集合的实现
- 1. 整数集合的实现
- 1.1 数据结构
- 1.2 初始化
- 1.3 添加元素
- 1.4 查找元素
- 1.5 删除元素
- 1.6 内存管理
- 图解
- 升级
- 2. 升级
- 2.1 升级的原因
- 2.2 升级的实现
- 2.3 升级步骤
- 2.4 升级示例
- 重点剖析
- 升级和好处
- 3.1 升级的灵活性
- 3.2 节约空间
- 内存节约机制
- 示例
- 升级的好处总结
- 重点剖析
- 降级
- 4.1 为什么不支持降级
- 4.2 降级的手动处理
- 重点剖析
- 总结
- 压缩列表
- 压缩列表的构成
- 1.1 压缩列表结构
- 1.2 头部
- 1.3 节点
- 1.4 尾部
- 1.5 图示
- 重点剖析
- 压缩列表节点的构成
- 2.1 `previous_entry_length`
- 示例
- 2.2 `Encoding`
- 示例
- 2.3 `Content`
- 示例
- 重点剖析
- 连锁反应
- 3.1 插入操作
- 示例
- 3.2 删除操作
- 示例
- 3.3 移动操作
- 示例
- 重点剖析
- 对象
- 对象的类型与编码
- 对象的类型
- 字符串对象(String)
- 编码转换
- 字符串命令的实现
- 列表对象(List)
- 编码转换
- 列表命令的实现
- 哈希对象(Hash)
- 编码转换
- 哈希命令的实现
- 集合对象(Set)
- 编码转换
- 集合命令的实现
- 有序集合对象(Sorted Set)
- 编码转换
- 有序集合命令的实现
- 总结:转换条件
- 类型检查与命令多态
- 类型检查的实现
- 多态命令的实现
- 内存回收
- 内存回收
- 内存回收的实现
- 对象共享
- 对象共享的实现
- 对象的空转时长
- 对象空转时长的实现
SDS的定义
SDS(Simple Dynamic String)是一种由Redis引入的字符串数据结构,旨在提高字符串处理的效率和灵活性。与C语言中的传统字符串(C字符串)相比,SDS提供了一些额外的功能和改进,特别是在内存管理和性能方面。
SDS的结构
struct sdshdr { int len; // 当前字符串长度 int free; // 剩余可用空间 char buf[]; // 字符数组 }; 图示结构
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
SDS字段解析
- len:表示当前SDS字符串的长度,不包括终止
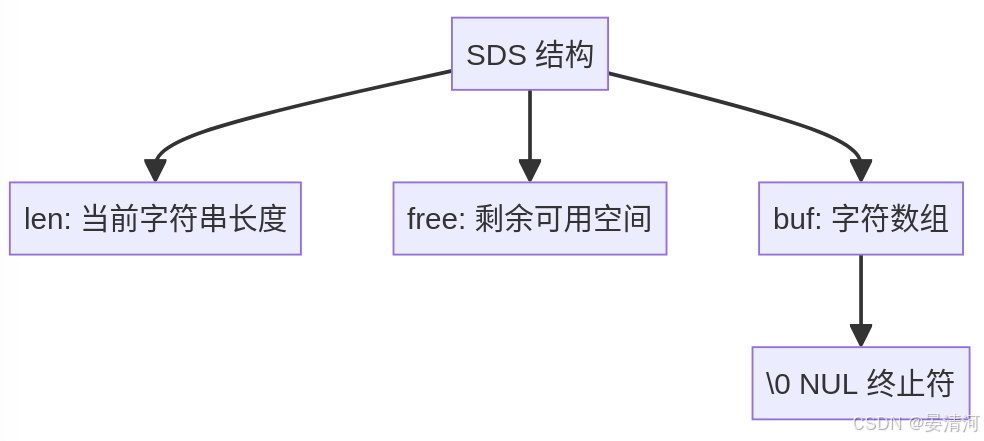
符。 - free:表示在
buf中未使用的空间量。 - buf:实际存储字符串内容的字符数组,长度为
len+free1(加1是为了存储空终止符\0)。
SDS的特点
- 动态扩展:SDS能够根据需要自动扩展和收缩。当字符串内容增加时,SDS会重新分配足够的空间以容纳新内容,同时保留一定的预留空间,以减少未来的扩展操作。
- 存储长度信息:SDS在结构体中存储了字符串的长度,这使得获取字符串长度的操作时间复杂度为O(1),即常数时间复杂度。
- 二进制安全:SDS能够存储二进制数据,而不仅仅是文本数据。这是因为SDS内部使用的
len字段来确定字符串的长度,而不是依赖于空终止符\0。 - 减少缓冲区溢出:由于SDS能够自动管理内存,因此可以有效避免缓冲区溢出的问题。
通过这些特点,SDS在处理字符串操作时比传统的C字符串更为高效和安全。接下来将详细介绍SDS和C字符串的区别。
SDS和字符串的区别
长度存储:
- C字符串:通过空终止符(
\0)确定字符串长度,需要遍历整个字符串,时间复杂度为O(n)。 - SDS:通过结构体中的
len字段存储字符串长度,获取长度的操作时间复杂度为O(1)。
内存****管理:
- C字符串:需要手动管理内存,容易发生缓冲区溢出。
- SDS:自动管理内存,防止缓冲区溢出,提供更安全的字符串操作。
内存****分配:
- C字符串:每次修改字符串内容都可能导致内存重新分配。
- SDS:通过空间预分配和惰性空间释放减少内存重新分配的次数。
二进制安全:
- C字符串:不适合存储二进制数据,因为会误将二进制数据中的
\0视为字符串终止符。 - SDS:可以存储二进制数据,因为其长度是通过
len字段确定的,而不是依赖空终止符。
兼容性:
- C字符串:直接使用标准库函数进行字符串操作。
- SDS:兼容部分C字符串函数,同时提供更高效和安全的操作。
常数复杂度获取字符串的长度
SDS在结构体中存储了字符串的长度,这使得获取字符串长度的操作时间复杂度为O(1),即常数时间复杂度。这比C字符串的O(n)复杂度要高效得多。
int sdslen(const sds s) { struct sdshdr *sh = (void*)(s - (sizeof(struct sdshdr))); return sh->len; } 杜绝缓冲区的溢出
由于SDS能够自动管理内存,因此可以有效避免缓冲区溢出的问题。每次操作时,SDS都会检查是否有足够的空间,如果没有,就会自动扩展。
减少修改字符串时的内存分配次数
SDS通过以下两种方式减少内存重新分配的次数:
- 空间预分配:
- 当SDS需要扩展时,会多分配一些额外的空间,以便未来的操作可以直接利用这部分空间,而不需要再次进行内存分配。
- 这个操作使得将扩展N次操作的行为,限制到最多执行N次内存分配
s = sdsMakeRoomFor(s, addlen); - 惰性空间释放:
- 当SDS缩小时,并不会立即释放多余的内存,而是将其标记为未使用的空间,以便将来可以重用。
void sdsIncrLen(sds s, int incr) { struct sdshdr *sh = (void*)(s - (sizeof(struct sdshdr))); sh->len += incr; sh->free -= incr; } 二进制安全
SDS能够存储和处理二进制数据,而不仅仅是文本数据。这是因为SDS内部使用的len字段来确定字符串的长度,而不是依赖于空终止符\0。
兼容部分c字符串函数
SDS兼容部分C字符串函数,使得开发者可以方便地将其与C字符串互换使用。
sds s = sdsnew("hello"); s = sdscat(s, " world"); printf("%s\n", s); // 输出:hello world 总结
SDS通过引入长度存储、动态扩展、空间预分配和惰性空间释放等机制,在处理字符串操作时比传统的C字符串更加高效和安全。同时,SDS的二进制安全特性和兼容部分C字符串函数的设计,使其成为一种灵活且功能强大的字符串数据结构。在Redis中,SDS的应用极大地提高了系统的性能和可靠性。
链表
链表和链表节点的实现
Redis 是一个高性能的键值存储系统,使用多种数据结构来实现其功能,其中链表是一种重要的数据结构。链表在 Redis 中用于实现列表类型的数据(List)。下面将详细介绍 Redis 中链表的实现,包括链表和链表节点的实现,并进行总结。
- 链表和链表节点的实现
在 Redis 中,链表通过两个主要的结构体来实现:list 和 listNode。
链表节点(listNode)
链表节点包含了节点的数据以及指向前驱和后继节点的指针。其结构体定义如下:
typedef struct listNode { struct listNode *prev; // 指向前一个节点 struct listNode *next; // 指向后一个节点 void *value; // 节点的值 } listNode; 链表(list)
链表结构体包含了指向头节点和尾节点的指针,以及链表的长度和用于节点值操作的函数指针。其结构体定义如下:
typedef struct list { listNode *head; // 指向链表的头节点 listNode *tail; // 指向链表的尾节点 void *(*dup)(void *ptr); // 节点值复制函数 void (*free)(void *ptr); // 节点值释放函数 int (*match)(void *ptr, void *key); // 节点值匹配函数 unsigned long len; // 链表的长度(节点数) } list; 链表的操作
链表的基本操作包括创建链表、释放链表、添加节点、删除节点等。
创建链表
list *listCreate(void) { struct list *list; if ((list = malloc(sizeof(*list))) == NULL) return NULL; list->head = list->tail = NULL; list->len = 0; list->dup = NULL; list->free = NULL; list->match = NULL; return list; } 释放链表
void listDelNode(list *list, listNode *node) { if (node->prev) node->prev->next = node->next; else list->head = node->next; if (node->next) node->next->prev = node->prev; else list->tail = node->prev; if (list->free) list->free(node->value); free(node); list->len--; } 添加节点
Redis 提供了在链表头部和尾部添加节点的功能:
list *listAddNodeHead(list *list, void *value) { listNode *node; if ((node = malloc(sizeof(*node))) == NULL) return NULL; node->value = value; if (list->len == 0) { list->head = list->tail = node; node->prev = node->next = NULL; } else { node->prev = NULL; node->next = list->head; list->head->prev = node; list->head = node; } list->len++; return list; } list *listAddNodeTail(list *list, void *value) { listNode *node; if ((node = malloc(sizeof(*node))) == NULL) return NULL; node->value = value; if (list->len == 0) { list->head = list->tail = node; node->prev = node->next = NULL; } else { node->prev = list->tail; node->next = NULL; list->tail->next = node; list->tail = node; } list->len++; return list; } 删除节点
void listDelNode(list *list, listNode *node) { if (node->prev) node->prev->next = node->next; else list->head = node->next; if (node->next) node->next->prev = node->prev; else list->tail = node->prev; if (list->free) list->free(node->value); free(node); list->len--; } 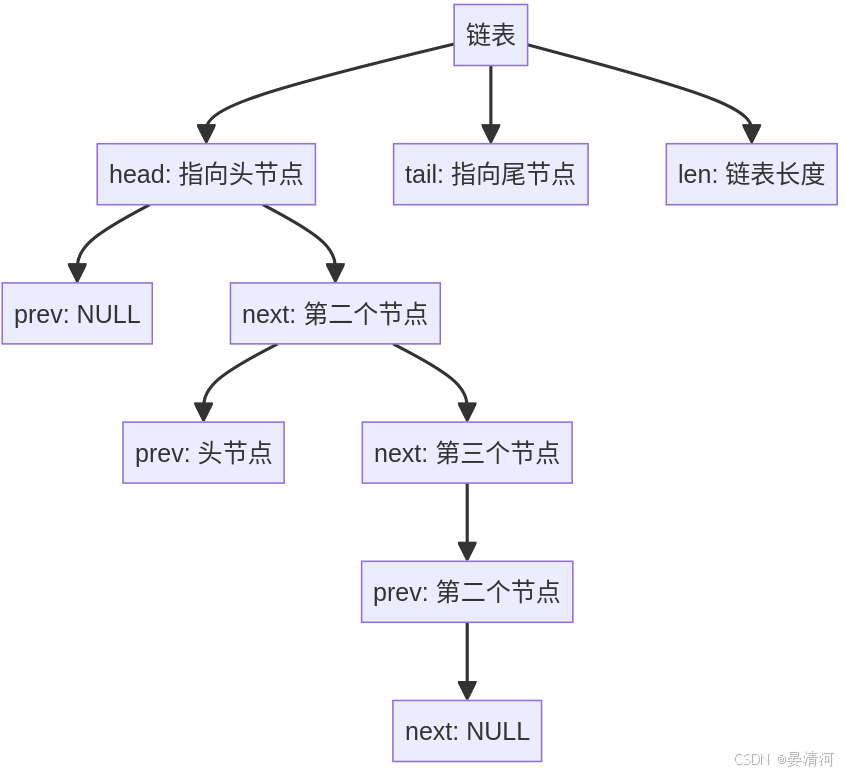
总结
Redis中的链表实现为双向链表,具备以下特点和优势:
- 双向链表结构:
- 链表节点(
listNode****):每个节点包含指向前后节点的指针和一个指向数据的指针。 - 链表**(
list)**:链表维护对头节点和尾节点的指针,以及链表的长度。
- 链表节点(
- 操作效率:
- 插入与删除:链表提供了高效的插入和删除操作,尤其是在链表的头部和尾部。插入和删除操作的时间复杂度为O(1)。
- 遍历:通过双向指针,可以高效地从任意节点向前或向后遍历链表。
- 内存****管理:
- 动态扩展:链表可以动态扩展和收缩,适合需要频繁插入和删除操作的场景。
- 内存****利用:每个节点占用额外的指针空间(前后节点指针),相较于单向链表,双向链表在内存使用上有所增加,但操作灵活性更高。
- 应用场景:
- Redis中的链表被广泛应用于实现列表、消息队列、任务队列等数据结构和功能。
- 链表的双向性使得其在某些场景下比单向链表更加高效,例如双向遍历和从任意节点快速访问。
重点回顾
- 链表节点(
listNode****):包含前驱、后继指针和数据指针。 - 链表**(
list)**:管理链表的头、尾和长度。 - 效率:双向链表的插入和删除操作时间复杂度为O(1),适合频繁操作的场景。
- 内存****管理:支持动态扩展,但每个节点多占用一些额外内存。
- 应用:适用于实现各种复杂数据结构和功能,如列表和队列。
字典
字典的实现
Redis中的字典(dict)是一个重要的数据结构,通常用于存储键值对。Redis的字典实现是基于哈希表的,提供了高效的查找、插入和删除操作。下面详细介绍Redis字典的实现,包括哈希表、哈希表节点和字典本身的结构。
在Redis中,字典实现使用了两个哈希表来存储键值对。这两个哈希表用于支持高效的查找和管理字典中的数据。
- 哈希表****的结构:
typedef struct dictEntry { void *key; // 键 union { void *val; // 值 uint64_t u64; int64_t s64; } v; // 值 struct dictEntry *next; // 指向下一个哈希表节点的指针(用于解决哈希冲突) } dictEntry; typedef struct dict { dictType *type; // 指向字典类型的指针(用于定义操作字典的函数) void *privdata; // 私有数据(可以用来存储特定于字典的额外数据) dictEntry **ht[2]; // 哈希表的数组(支持两个哈希表用于rehash) unsigned long size; // 当前哈希表的大小(桶的数量) unsigned long sizemask; // 哈希表的掩码(用于计算哈希桶的索引) unsigned long used; // 当前哈希表中的键值对数量 } dict; - 哈希表节点(
dictEntry****):- key:存储键的指针。
- v:存储值的联合体,可以存储不同类型的数据。
- next:指向下一个哈希表节点的指针,用于解决哈希冲突。
- 字典(
dict):- type:指向字典类型的指针,包含操作字典的函数,如比较键、计算哈希值等。
- privdata:用于存储特定于字典的额外数据。
- ht:两个哈希表(
ht[0]和ht[1]),用于支持rehash操作。 - size:当前哈希表的大小(桶的数量)。
- sizemask:掩码,用于计算哈希桶的索引。
- used:当前哈希表中键值对的数量。
图示结构
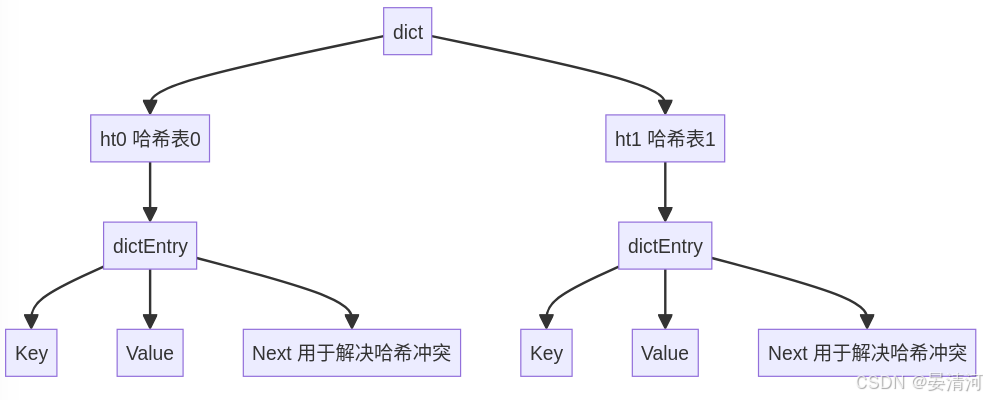
详细解释
- 哈希表:Redis使用两个哈希表来实现字典。每个哈希表包含多个桶,每个桶可以存储一个或多个
dictEntry节点。哈希表通过哈希函数将键映射到桶中。 - 哈希表****节点:每个
dictEntry节点包含一个键、一个值和一个指向下一个节点的指针。这个指针用于解决哈希冲突,即多个键被映射到同一个桶时,通过链表结构存储在同一个桶中。 - 字典结构:
dict结构体包含两个哈希表,用于实现rehash操作,即在哈希表扩展或收缩时,逐步将数据从一个哈希表迁移到另一个哈希表中。type和privdata用于定义字典操作和存储额外数据,size、sizemask和used用于管理哈希表的大小和当前数据量。
哈希算法
在Redis中,哈希算法是实现字典(dict)高效查找、插入和删除操作的核心。哈希算法的主要任务是将键映射到哈希表中的桶(bucket)中。下面详细介绍Redis中的哈希算法,包括哈希函数的定义和使用。
哈希函数
哈希函数的作用是将一个键(key)映射到哈希表中的一个位置(桶)。在Redis中,使用了不同的哈希函数来提高哈希表的性能和均匀性。
Redis使用的哈希函数:
- Redis使用了
djb2哈希函数和murmurhash哈希函数。
- Redis使用了
djb2:
-
unsigned long hashFunction(unsigned char *key) { unsigned long hash = 5381; int c; while ((c = *key++)) hash = ((hash << 5) + hash) + c; /* hash * 33 + c */ return hash; }
-
- djb2是一种简单而高效的哈希函数,通过对输入字符进行位移和累加操作来生成哈希值。
- murmurhash:
-
unsigned int murmurhash2(const void *key, int len, unsigned int seed) { const unsigned int m = 0x5bd1e995; const int r = 24; unsigned int h = seed ^ len; const unsigned char *data = (const unsigned char *)key; while (len >= 4) { unsigned int k = *(unsigned int *)data; k *= m; k ^= k >> r; k *= m; h *= m; h ^= k; data += 4; len -= 4; } switch (len) { case 3: h ^= data[2] << 16; case 2: h ^= data[1] << 8; case 1: h ^= data[0]; h *= m; } h ^= h >> 13; h *= m; h ^= h >> 15; return h; }
-
- murmurhash是一种非加密哈希函数,具有良好的性能和较低的碰撞率,适合用于哈希表等数据结构。
哈希桶索引计算
哈希函数生成的哈希值需要通过掩码操作来确定哈希桶的索引。掩码操作用于将哈希值限制在哈希表的范围内。
计算桶索引:
-
unsigned long index = hash & dict->sizemask;
-
hash是哈希函数生成的哈希值。dict->sizemask是哈希表大小减1(用于限制索引在桶数组的范围内)。
图示结构
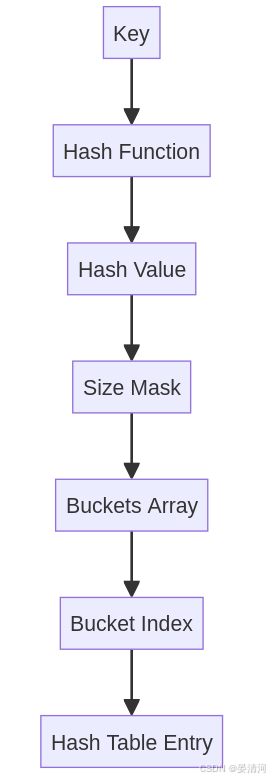
- Key:输入的键。
- Hash Function:哈希函数将键转换为哈希值。
- Hash Value:哈希函数计算出的哈希值。
- Size Mask:掩码操作将哈希值限制在哈希表的桶范围内。
- Buckets Array:哈希表的桶数组。
- Bucket Index:通过掩码计算得到的桶索引。
- Hash TableEntry:存储在桶中的哈希表条目。
关键点总结
- 哈希函数:Redis使用
djb2和murmurhash等哈希函数将键映射到哈希表的桶中,确保高效的存储和查找操作。 - 哈希桶索引计算:通过掩码操作将哈希值限制在哈希表的桶范围内,确保哈希表的均匀性和性能。
- 哈希表:Redis使用两个哈希表(
ht[0]和ht[1])来支持rehash操作,并使用哈希函数和掩码计算桶索引。
哈希算法在Redis中起到了至关重要的作用,确保了字典操作的高效性和哈希表的性能。接下来,将详细介绍如何解决键冲突。
解决键冲突
在哈希表中,键冲突(Hash Collision)指的是不同的键通过哈希函数计算得到相同的哈希值,从而映射到哈希表的同一个桶。Redis使用了一些技术来有效地解决键冲突,确保哈希表的性能和正确性。
解决键冲突的策略
Redis采用链式地址法(Chaining)来解决哈希冲突。这种方法在每个桶中维护一个链表,用于存储具有相同哈希值的多个条目。
链式地址法(Chaining):
每个哈希表的桶(bucket)是一个链表的头指针。若多个键通过哈希函数计算得到相同的桶索引,则这些键值对会被存储在同一个链表中。
链表****节点(
**dictEntry**):每个节点包含一个键、一个值和一个指向下一个节点的指针。通过这种方式,可以在每个桶中存储多个键值对,从而解决哈希冲突。
哈希冲突的处理流程
- 计算****哈希值:使用哈希函数计算键的哈希值。
- 计算桶索引:通过掩码操作将哈希值映射到哈希表的桶数组中。
- 插入或查找:
- 插入:若桶中已有节点(链表不为空),则将新节点插入到链表的头部或尾部(取决于实现)。如果桶为空,则直接将新节点作为桶的第一个节点。
- 查找:遍历桶中的链表,查找具有相同键的节点。
图示结构
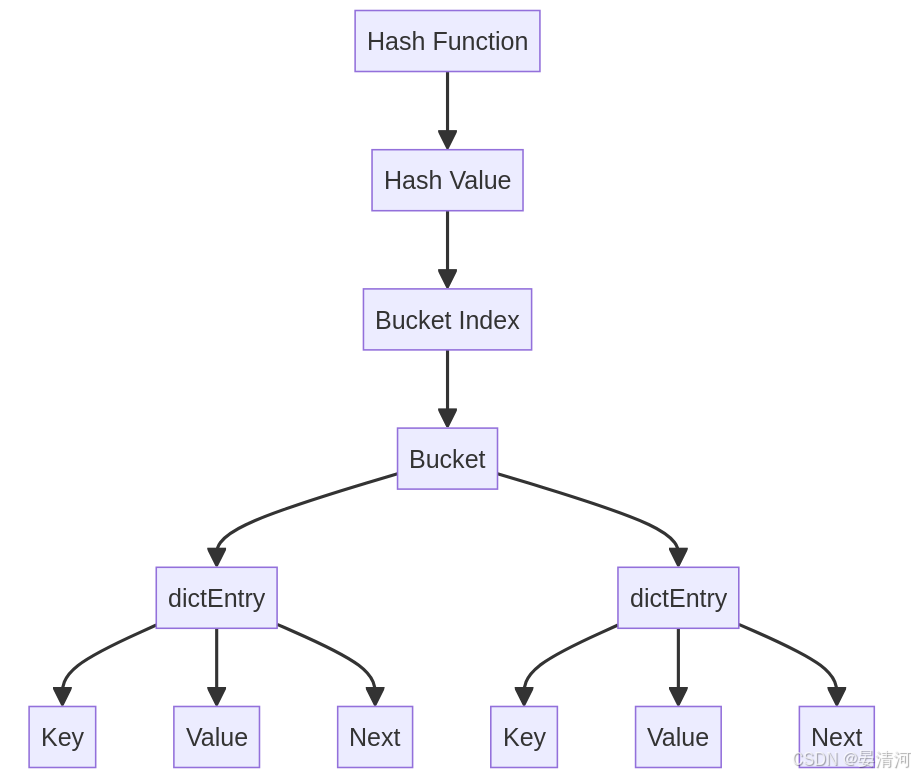
- Hash Function:计算键的哈希值。
- Hash Value:哈希函数生成的哈希值。
- Bucket Index:通过掩码计算得到的桶索引。
- Bucket:哈希表中的桶(链表的头指针)。
- dictEntry:链表中的节点,包含键、值和指向下一个节点的指针。
关键点总结
- 链式地址法:Redis通过在每个桶中维护一个链表来解决哈希冲突,允许多个键值对存储在同一个桶中。
- 插入和查找:在插入新条目时,将其添加到链表中;在查找时,遍历链表以找到具有匹配键的条目。
- 性能:链式地址法在处理键冲突时能够有效地管理哈希表,保证操作的时间复杂度接近O(1),尽管在最坏情况下,所有条目都可能位于同一个链表中,从而使操作变为O(n)。
链式地址法是Redis解决哈希冲突的主要策略,它确保了哈希表在处理冲突时的效率和稳定性。接下来,将详细介绍Redis中的rehash过程。
4. Rehash
在Redis中,rehash(重新哈希)是动态调整哈希表大小的过程,旨在应对哈希表中键值对数量的变化,保持哈希表的性能和效率。Redis支持哈希表的扩展和收缩,以适应不同的负载需求。
哈希表的扩展和收缩
- 哈希表****的扩展: 当哈希表中的键值对数量达到一定阈值时,为了提高哈希表的性能和避免频繁的键冲突,Redis会扩展哈希表的大小。扩展过程包括创建一个更大的哈希表,并将旧哈希表中的所有条目迁移到新哈希表中。
- 哈希表****的收缩: 当哈希表中的键值对数量减少到一定程度时,为了节省内存,Redis会收缩哈希表的大小。收缩过程类似于扩展过程,包括创建一个更小的哈希表,并将旧哈希表中的所有条目迁移到新哈希表中。
Rehash过程
Redis的rehash过程通过以下步骤实现哈希表的扩展和收缩:
- 创建新****哈希表:
- 在扩展时,创建一个大小等于user*2的2^n
- 在收缩时,创建一个大小等于user*2的2^n。
- 迁移数据:
- 逐步将旧哈希表中的条目迁移到新哈希表中。
- 迁移过程会在
rehash操作期间交替进行,以避免在迁移过程中影响哈希表的性能。
- 更新哈希表指针:
- 在完成迁移后,更新字典结构中的哈希表指针,将其指向新哈希表。
- 释放旧哈希表内存:
- 释放旧哈希表占用的内存空间。
渐进式 Rehash
为了避免在rehash过程中出现长时间的阻塞,Redis采用了渐进式rehash。渐进式rehash通过分批迁移条目,降低了对系统性能的影响。
- 渐进式 Rehash 执行期间的哈希表操作:
- 分批迁移:每次
rehash操作会迁移一定数量的条目,而不是一次性迁移所有条目。 - 同时操作:在执行渐进式
rehash的同时,允许对原哈希表进行读写操作,确保系统的高可用性。
- 分批迁移:每次
图示结构
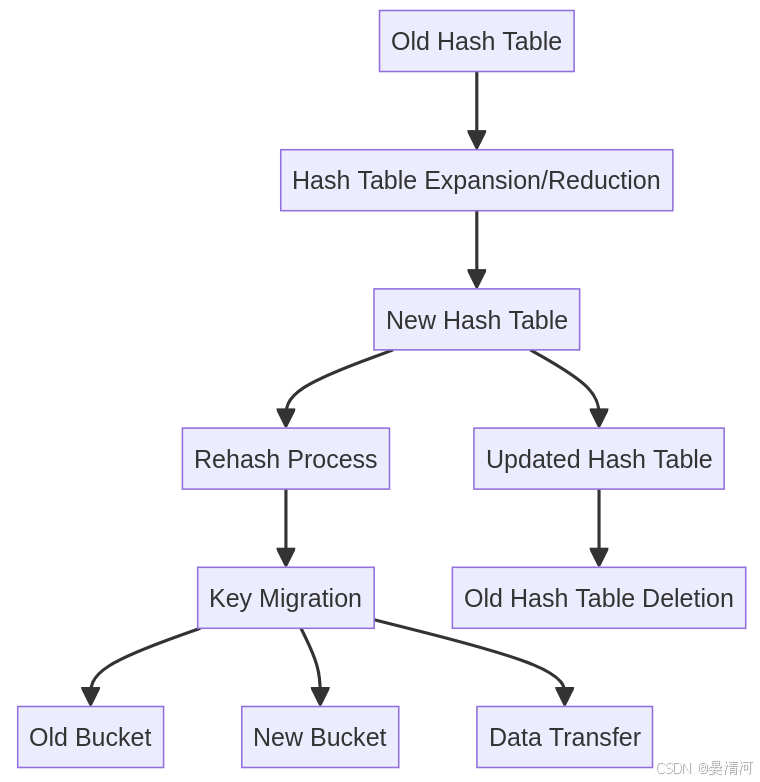
- OldHash Table:原哈希表。
- NewHash Table:新创建的哈希表(扩展或收缩后的大小)。
- Rehash Process:
rehash过程,包括迁移数据。 - Key Migration:将旧哈希表中的键值对迁移到新哈希表。
- Old Bucket:原哈希表中的桶。
- New Bucket:新哈希表中的桶。
- Data Transfer:数据迁移。
- UpdatedHash Table:更新后的哈希表,指向新哈希表。
- OldHash TableDeletion:删除旧哈希表以释放内存。
关键点总结
- 哈希表****的扩展:当键值对数量增加时,通过创建更大的哈希表来提高性能,减少冲突。
- 哈希表****的收缩:当键值对数量减少时,通过创建更小的哈希表来节省内存。
- 渐进式 Rehash:Redis通过分批迁移条目来执行
rehash,降低对系统性能的影响,同时允许对哈希表进行操作。 - 性能影响:渐进式
rehash避免了长时间的阻塞,确保系统在rehash期间的高可用性。
Redis中的rehash机制通过动态调整哈希表大小,确保了哈希表在各种负载下的高效性能和内存利用率。接下来,将详细介绍渐进式rehash的执行过程及其在操作期间的影响。
Rehash的条件总结
在Redis中,rehash(重新哈希)是哈希表动态调整大小的过程。rehash的触发条件受当前负载因子和系统状态的影响,特别是在不同情况下的负载因子阈值设定有所不同。以下是重新总结的rehash条件:
1. 哈希表****扩展条件
- 无后台持久化命令时:
- 负载因子(Load Factor):当哈希表的负载因子达到1(即哈希表中的键值对数量与桶的数量相等)时,Redis会触发哈希表的扩展。
- 条件触发:负载因子达到1时,Redis会启动扩展过程,创建一个更大的哈希表,并将数据迁移到新的哈希表中。
- 有后台持久化命令时:
- 负载因子(Load Factor):当哈希表的负载因子达到5(即哈希表中的键值对数量是桶数量的5倍)时,Redis会触发哈希表的扩展。
- 条件触发:为了避免在后台任务执行期间(如
BGSAVE、BGREWRITEAOF等)对性能造成严重影响,Redis在后台持久化命令执行期间会提高负载因子的触发阈值,从1提高到5。
2. 哈希表****收缩条件
- 负载因子下降:
- 负载因子低于下限:当哈希表的负载因子低于设定的下限(通常为0.1)时,Redis会触发哈希表的收缩。
- 条件触发:负载因子下降到设定下限时,Redis会启动收缩过程,创建一个更小的哈希表,并将数据迁移到新的哈希表中。
3. 渐进式 Rehash
- 渐进式 Rehash 触发:Redis在扩展或收缩时采用渐进式
rehash,分批迁移数据,减少对系统性能的影响。 - 触发条件:
- 定期触发:
dictRehash函数会定期触发迁移过程,确保迁移操作在后台平稳进行。 - 与后台操作共存:渐进式
rehash允许与后台任务(如BGSAVE、BGREWRITEAOF等)共存,减少对主线程性能的干扰。
- 定期触发:
关键点总结
- 无后台持久化命令时:哈希表的负载因子达到1时触发扩展。
- 有后台持久化命令时:负载因子达到5时触发扩展,以避免后台任务对性能的影响。
- 收缩条件:负载因子下降到设定下限(通常为0.1)时触发收缩。
- 渐进式 Rehash:通过分批迁移条目进行
rehash,允许后台任务与rehash过程并行进行,确保系统的稳定性和高效性。
这些条件确保了Redis在不同负载和系统状态下能够动态调整哈希表的大小,优化性能和内存使用。
重点回顾
字典的实现
- 哈希表:
- Redis的字典基于哈希表实现,使用开放地址法来管理键值对。
- 哈希表由若干个桶(数组元素)组成,每个桶可能包含一个链表来处理哈希冲突。
- 哈希算法
- 哈希函数:
- Redis使用哈希函数将键映射到哈希表的桶索引。
- 哈希函数的质量直接影响哈希表的性能和冲突概率。
- 解决键冲突
- 链式地址法(Chaining):
- 采用链式地址法来处理哈希冲突,即在每个桶中维护一个链表。
- 节点通过指针连接,形成一个链表,允许在同一个桶中存储多个键值对。
- Rehash
- 哈希表****的扩展和收缩:
- 扩展:当负载因子超过设定阈值时,Redis会扩展哈希表,创建更大的哈希表,并迁移数据。
- 收缩:当负载因子下降到设定下限时,Redis会收缩哈希表,创建更小的哈希表,并迁移数据。
- 渐进式 Rehash:
- Redis通过渐进式
rehash在后台分批迁移条目,以减少对系统性能的影响。 - 渐进式
rehash允许与后台任务(如BGSAVE、BGREWRITEAOF等)并行执行,保持系统的高效性。
- Redis通过渐进式
- 触发条件:
- 无后台持久化命令时:负载因子达到1时触发扩展。
- 有后台持久化命令时:负载因子达到5时触发扩展。
- 收缩条件:负载因子下降到设定下限(通常为0.1)时触发收缩。
- 重点回顾
- 字典的结构:包括两个哈希表(用于渐进式
rehash)、键值对节点和管理信息。 - 哈希算法:影响哈希表性能的关键因素。
- 键冲突解决:使用链式地址法,通过链表解决冲突。
- Rehash机制:包括哈希表的扩展和收缩,及渐进式
rehash的实现和条件。
这些知识点构成了Redis字典的核心,实现了高效的键值对存储和管理。
跳跃表
跳跃表的实现
跳跃表是一种有效的、随机化的数据结构,支持在对数时间内进行插入、删除和查找操作。以下是跳跃表的详细实现,包括节点结构及其各部分功能的说明,以及如何通过源码理解跳跃表的实现。
跳跃表节点
跳跃表中的每个节点由以下几个关键部分构成:
1. 层(Level)
跳跃表节点的层数决定了它在跳跃表中的高度。每个节点可以有多个层,最底层(Level 0)包含所有节点。每上一层,节点的数量递减,层数越高,节点能够覆盖的范围越大。
示意图:
2. 前进指针(Forward Pointers)
每层的前进指针指向当前层中下一个节点。这些指针使得在同一层中可以快速遍历到下一个节点。
3. 跨度(Skip)
节点的跨度指的是在跳跃表中,节点在其层级上的跳跃范围。节点在较高层级上能够跨越更多的节点,这加快了查找的速度。
4. 后退指针(Backward Pointers)
在跳跃表中,为了支持双向遍历,节点还可以包含后退指针,指向同一层中前一个节点。这使得在查找和删除操作时可以在反方向进行遍历。
5. 分值和成员(Score and Member)
每个节点包含一个分值(score)和一个成员(member)。分值用于排序和查找,而成员则是实际存储的数据。
源码结合
在 Redis 源码中,跳跃表的实现通常包括以下结构体和函数:
1. zskiplistNode
在 Redis 源码中,跳跃表节点的定义如下:
typedef struct zskiplistNode { sds obj; // 节点的成员对象 double score; // 节点的分值 struct zskiplistNode **forward; // 前进指针数组 struct zskiplistNode *backward; // 后退指针 unsigned int level; // 节点的层数 } zskiplistNode; obj:存储成员的数据。score:存储分值。forward:指向当前节点在不同层的前进指针数组。backward:指向当前节点在同一层的后退指针。level:表示当前节点的层数。
2. zskiplist
跳跃表的定义:
typedef struct zskiplist { struct zskiplistNode *header; // 跳跃表的头节点 struct zskiplistNode *tail; // 跳跃表的尾节点 unsigned long length; // 跳跃表的长度 int level; // 跳跃表的最大层数 } zskiplist; header:跳跃表的头节点。tail:跳跃表的尾节点。length:跳跃表的节点数量。level:跳跃表的最大层数。
3. 主要函数
- 插入节点:
zslInsert函数实现了将节点插入到跳跃表中。 - 查找节点:
zslFind函数实现了在跳跃表中查找节点。 - 删除节点:
zslDelete函数实现了从跳跃表中删除节点。
总结
跳跃表通过多层链表结构实现高效的数据存取。每个节点包含多个层,每层有前进和后退指针,以支持快速的查找和遍历操作。节点的层数、前进指针、跨度、后退指针和分值成员是跳跃表的关键组成部分。通过源码可以看到 Redis 中跳跃表的具体实现,包括节点结构和主要操作函数。
跳跃表
跳跃表是一种用于有序集合的高效数据结构,它通过多层链表的设计,使得在对数时间内进行插入、删除和查找操作成为可能。以下是跳跃表的主要实现细节和关键概念:
1. 跳跃表的节点结构
跳跃表中的每个节点包含以下几个部分:
- 层(Level):节点可以有多个层,每一层通过前进指针(forward pointer)连接到同一层中的下一个节点。层数越高,节点能够跨越的范围越大,从而加快查找速度。
- 前进指针(Forward Pointers):每一层的前进指针指向同一层中下一个节点,这些指针使得在层内能够快速遍历到下一个节点。
- 跨度(Skip):节点在不同层级上的跳跃范围。节点在较高层级上能够跨越更多的节点,提高查找效率。
- 后退指针(Backward Pointer):用于支持双向遍历的指针,指向同一层中的前一个节点。
- 分值和成员(Score and Member):每个节点存储一个分值(用于排序)和一个成员(存储实际数据)。
节点示意图:
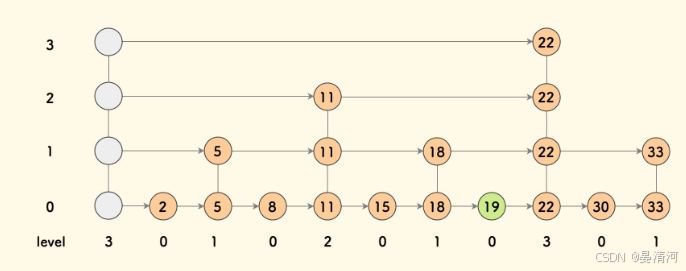
2. 跳跃表的结构
跳跃表主要包括以下几个结构部分:
- 头节点(Header Node):跳跃表的起始节点,通常不存储实际数据,而是用于简化其他节点的操作。
- 尾节点(Tail Node):跳跃表的终止节点,标记跳跃表的结束,通常也不存储实际数据。
- 层级(Levels):节点可以有多个层,每层在跳跃表的链表中建立不同的链接,用于加速查找过程。
跳跃表示意图:
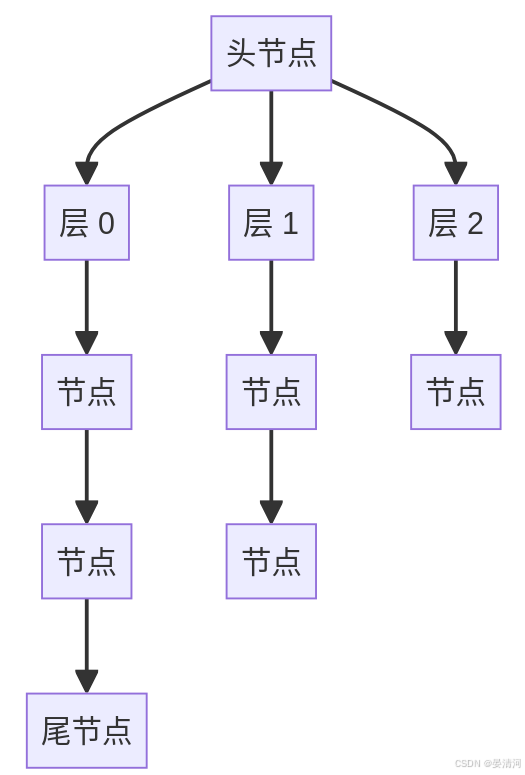
3. 跳跃表的操作
- 查找(Search):从跳跃表的最高层开始,利用前进指针向下跳跃,逐层向下直到找到目标节点或到达最底层。这个过程的时间复杂度是 O(log N)。
- 插入(Insert):在插入新节点时,首先在最底层插入,然后随机决定该节点的层数,并在每一层中更新前进指针。插入操作的时间复杂度也是 O(log N)。
- 删除(Delete):删除节点时,需要在所有包含该节点的层中更新前进指针,并释放节点的内存。删除操作的时间复杂度为 O(log N)。
4. 跳跃表的优势
- 高效性:通过多层次索引,跳跃表可以在对数时间内完成查找、插入和删除操作。
- 简单性:跳跃表实现相对简单,不需要像平衡树那样复杂的平衡操作。
- 动态调整:跳跃表的层数是通过随机算法动态调整的,这减少了维护的复杂性。
总结
跳跃表通过多层链表结构实现高效的数据存取。每个节点包含多层链表,每层通过前进和后退指针进行连接,支持快速查找和操作。跳跃表在插入、查找和删除操作上均提供了对数时间复杂度的性能,适合用于实现有序集合和需要高效排序的应用场景。
整数集合
整数集合的实现
1. 整数集合的实现
整数集合(intset)是Redis用来存储整数值的有序集合。它的实现采用了紧凑的内存布局,以便在存储和处理整数集合时节省空间和提高效率。
1.1 数据结构
整数集合的底层数据结构定义如下:
typedef struct intset { uint32_t encoding; // 编码方式 uint32_t length; // 集合中的元素数量 int8_t contents[]; // 保存元素的数组 } intset; encoding:表示整数集合中所有整数的编码方式。可能的值包括:INTSET_ENC_INT16(16位)INTSET_ENC_INT32(32位)INTSET_ENC_INT64(64位)
length:整数集合中的元素数量。contents:实际存储整数值的数组。它是一个灵活数组,长度根据需要动态分配。
1.2 初始化
整数集合的初始化函数如下:
intset *intsetNew(void) { intset *is = zmalloc(sizeof(intset)); is->encoding = INTSET_ENC_INT16; is->length = 0; return is; } 初始化时,整数集合的编码方式为INTSET_ENC_INT16,元素数量为0。
1.3 添加元素
当向整数集合中添加元素时,可能会触发编码升级。以下是添加元素的代码:
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) { uint8_t valenc = _intsetValueEncoding(value); uint32_t pos; if (success) *success = 1; if (valenc > intrev32ifbe(is->encoding)) { return intsetUpgradeAndAdd(is, value); } else { if (intsetSearch(is, value, &pos)) { if (success) *success = 0; return is; } is = intsetResize(is, intrev32ifbe(is->length)+1); if (pos < intrev32ifbe(is->length)) intsetMoveTail(is, pos, intrev32ifbe(is->length)); } _intsetSet(is, pos, value); is->length = intrev32ifbe(intrev32ifbe(is->length)+1); return is; } intsetAdd函数通过_intsetValueEncoding确定要添加的值的编码方式。- 如果新值的编码方式大于当前集合的编码方式,则调用
intsetUpgradeAndAdd进行升级并添加元素。 - 如果新值的编码方式不大于当前编码方式,则查找新值在集合中的插入位置,必要时调整数组长度并移动尾部元素。
1.4 查找元素
整数集合通过二分查找来查找元素:
uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) { int min = 0, max = intrev32ifbe(is->length)-1, mid = -1; int64_t cur; if (intrev32ifbe(is->length) == 0) { if (pos) *pos = 0; return 0; } while(max >= min) { mid = (min+max) >> 1; cur = _intsetGet(is, mid); if (value > cur) { min = mid+1; } else if (value < cur) { max = mid-1; } else { break; } } if (value == cur) { if (pos) *pos = mid; return 1; } else { if (pos) *pos = min; return 0; } } intsetSearch函数采用二分查找算法在整数集合中查找指定值。- 如果找到该值,则返回1,并将位置赋值给
pos。 - 如果未找到该值,则返回0,并将插入位置赋值给
pos。
1.5 删除元素
从整数集合中删除元素的代码如下:
intset *intsetRemove(intset *is, int64_t value, int *success) { uint8_t valenc = _intsetValueEncoding(value); uint32_t pos; if (success) *success = 0; if (valenc <= intrev32ifbe(is->encoding) && intsetSearch(is, value, &pos)) { is = intsetResize(is, intrev32ifbe(is->length)-1); if (pos < intrev32ifbe(is->length)-1) intsetMoveTail(is, pos+1, intrev32ifbe(is->length)-pos-1); is->length = intrev32ifbe(intrev32ifbe(is->length)-1); if (success) *success = 1; } return is; } intsetRemove函数首先确定要删除的值的编码方式。- 如果该值的编码方式不大于当前集合的编码方式,并且找到该值的位置,则调整数组长度并移动尾部元素。
- 最后更新集合的长度。
1.6 内存管理
intsetResize函数用于调整整数集合的内存大小:
static intset *intsetResize(intset *is, uint32_t len) { uint32_t size = len*intrev32ifbe(is->encoding); is = zrealloc(is, sizeof(intset)+size); return is; } 该函数根据新的长度重新分配内存,并返回调整后的整数集合。
图解
整数集合在内存中的布局如下:
+----------+----------+----------+ | encoding | length | contents | +----------+----------+----------+ | INT16 | 3 | 2, 5, 9| +----------+----------+----------+ encoding:16位整数编码length:集合中有3个元素contents:实际存储的整数值,按升序排列
重点剖析
编码方式:整数集合根据存储的整数值的大小动态选择最小的编码方式,以节省内存空间。支持的编码方式包括16位、32位和64位整数。
有序存储:整数集合中的元素按升序排列,有利于快速查找。
内存****紧凑:采用紧凑的内存布局,减少了内存碎片,提高了存储效率。
灵活升级:支持动态升级编码方式,以适应更大范围的整数值存储需求。
升级
2. 升级
2.1 升级的原因
当需要向整数集合中添加一个新元素,并且该元素的编码方式大于当前整数集合的编码方式时,Redis会进行升级操作,以便能够存储新的元素。升级操作可以保证整数集合能够存储更大范围的整数值,同时保持有序性。
2.2 升级的实现
升级操作在intsetAdd函数中实现,当新元素的编码方式大于当前整数集合的编码方式时,会调用intsetUpgradeAndAdd函数:
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) { uint8_t curenc = intrev32ifbe(is->encoding); uint8_t newenc = _intsetValueEncoding(value); int length = intrev32ifbe(is->length); is = intsetResize(is, length+1); while(length--) _intsetSet64(is, length+1, _intsetGet(is, length, curenc)); is->encoding = intrev32ifbe(newenc); if (value < 0) { _intsetSet(is, 0, value); } else { _intsetSet(is, intrev32ifbe(is->length), value); } is->length = intrev32ifbe(intrev32ifbe(is->length)+1); return is; } 2.3 升级步骤
确定当前和新编码方式:
curenc:当前整数集合的编码方式。newenc:新元素的编码方式。
调整整数集合的大小:
- 调用
intsetResize函数重新分配内存,使其能够容纳一个新元素。
- 调用
数据迁移:
- 从后向前遍历现有元素,将它们从当前编码方式转换为新编码方式,并移动到新的位置。
更新编码方式:
- 将整数集合的编码方式更新为新编码方式。
插入新元素:
- 根据新元素的值,决定将其插入到集合的起始位置或末尾。
更新元素数量:
- 更新整数集合的元素数量。
2.4 升级示例
假设一个整数集合使用16位编码存储了元素2和5,现在需要添加一个值为32768的新元素,这需要升级到32位编码。升级前后的内存布局如下:
升级前:
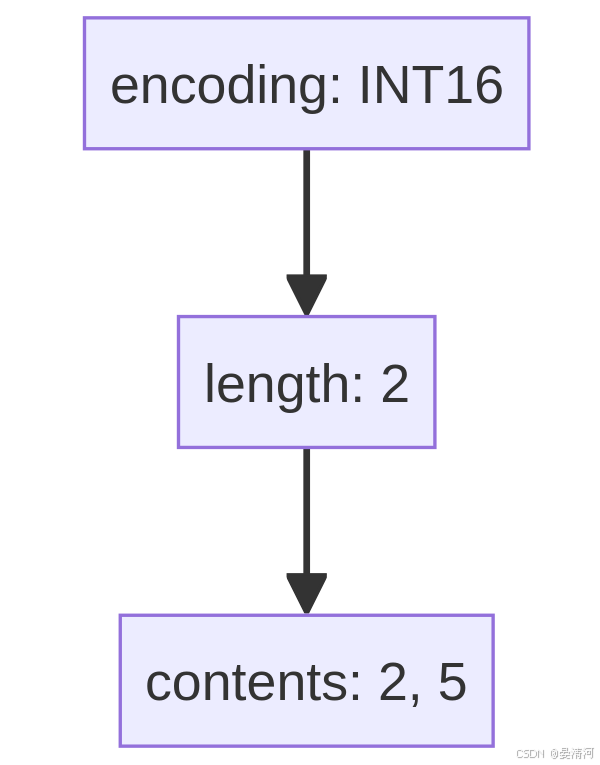
升级后:
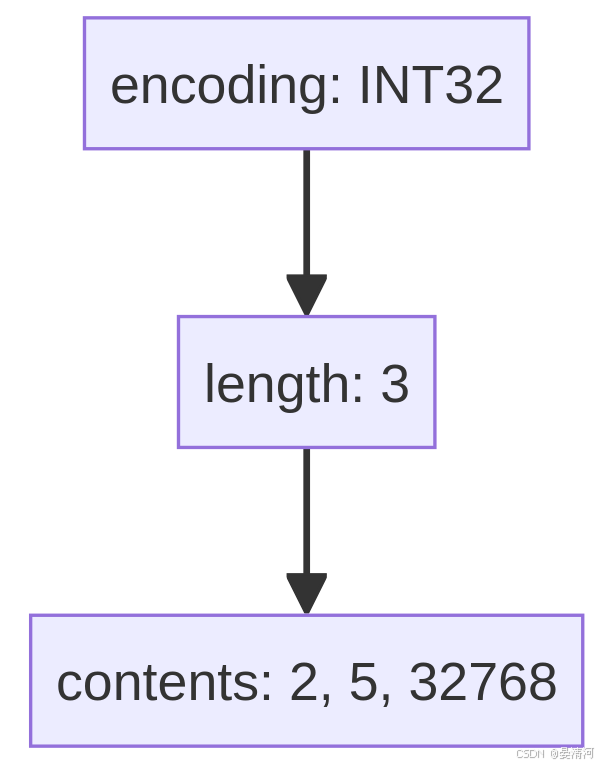
重点剖析
编码升级:升级操作确保整数集合能够存储更大范围的整数值,同时保持集合的有序性。
内存****调整:在升级过程中重新分配内存,保证新的元素可以被存储。
数据迁移:将现有元素从旧编码方式转换为新编码方式,并移动到新的位置。
灵活性:升级过程是灵活的,能够根据需要动态调整集合的编码方式,以适应不同范围的整数值。
升级和好处
Redis整数集合(intset)的升级机制有许多好处,尤其是在处理不同范围的整数时。以下将详细解释升级的灵活性和节约空间的好处。
3.1 升级的灵活性
灵活性是Redis整数集合升级的一个重要特性。这种灵活性体现在以下几个方面:
- 动态调整编码方式:整数集合会根据存储的整数值的实际范围,自动选择合适的编码方式(16位、32位或64位)。这样可以确保存储和处理效率的最大化。
- 自动升级:当需要存储一个超出当前编码范围的新值时,整数集合会自动升级编码方式,以适应新的值。这种自动升级机制简化了开发者的工作,无需手动干预。
3.2 节约空间
整数集合通过选择最小的编码方式来存储整数值,从而节约内存空间。这种机制在存储大量小整数时尤其有效。
内存节约机制
- 紧凑存储:整数集合根据存储的整数值的范围,选择合适的编码方式,以节约内存。例如,当所有值都在16位范围内时,使用16位编码存储。
- 按需升级:只有当需要存储超出当前编码范围的新值时才进行升级,避免不必要的内存开销。
示例
一个只包含小整数的集合:
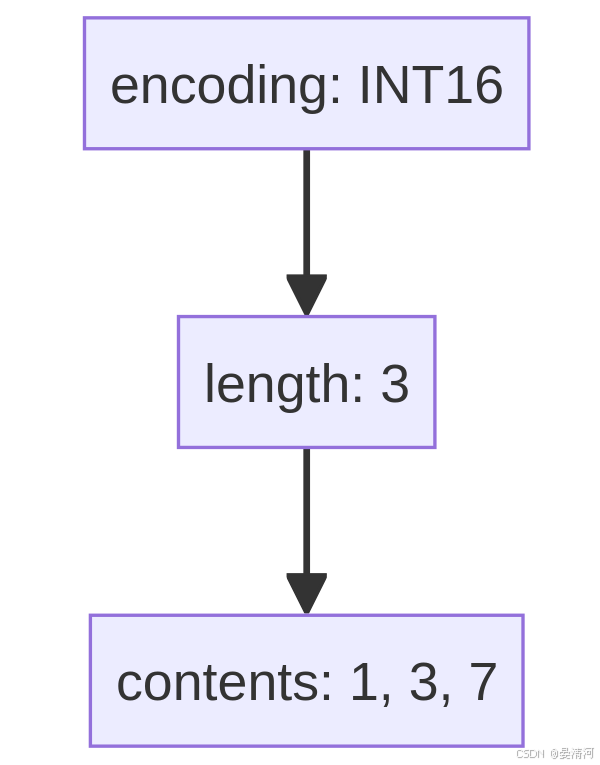
上述集合只需要使用16位编码,每个元素占用2字节,总共占用6字节。如果升级到32位编码,内存占用将翻倍,变为12字节。但只在必要时升级,从而避免了这种开销。
升级的好处总结
灵活性:
- 动态调整编码方式,适应不同范围的整数值。
- 自动升级机制,简化开发者的工作。
节约空间:
- 使用最小的编码方式存储整数,减少内存占用。
- 只有在必要时才升级编码方式,避免不必要的内存开销。
重点剖析
编码选择:根据整数值的实际范围动态选择合适的编码方式,以确保高效的存储和处理。
自动升级:当需要存储超出当前编码范围的新值时,整数集合自动升级编码方式,简化了开发者的操作。
内存****紧凑:通过选择最小的编码方式,整数集合可以有效地节约内存空间,尤其是在存储大量小整数时。
降级
Redis整数集合(intset)并不支持自动降级。也就是说,一旦整数集合的编码方式升级到更高的级别,它将保持该级别,即使所有的值都可以用较低的编码方式表示。这是为了简化实现和避免频繁的编码变更带来的开销。
4.1 为什么不支持降级
复杂性:实现降级会增加整数集合的复杂性。每次删除元素后,都需要检查是否可以降级,并可能涉及大量的数据迁移。
性能:频繁的编码变更(升级和降级)会影响性能。特别是在频繁插入和删除操作的场景中,降级操作会增加不必要的开销。
稳定性:保持编码方式不变可以提高稳定性,避免频繁的数据迁移带来的潜在问题。
4.2 降级的手动处理
尽管Redis整数集合不支持自动降级,但在某些场景下,开发者可以通过手动重新创建整数集合来实现降级。例如,当集合中的所有值都可以用较低的编码方式表示时,可以手动创建一个新的整数集合,并将所有值插入其中。
如果需要将其降级到32位编码,可以手动重新创建集合:
// 手动降级整数集合的示例代码 intset *intsetDowngrade(intset *is) { intset *new_is = intsetNew(); for (int i = 0; i < intrev32ifbe(is->length); i++) { int64_t value = _intsetGet(is, i); uint8_t success; new_is = intsetAdd(new_is, value, &success); } return new_is; } 重点剖析
- 自动降级的缺失:Redis整数集合不支持自动降级,以简化实现和避免性能开销。
- 手动降级:在某些情况下,开发者可以通过手动重新创建整数集合来实现降级。
总结
尽管Redis整数集合不支持自动降级,但了解如何手动降级可以帮助开发者在需要时优化内存使用。保持整数集合的编码方式稳定可以简化实现,提高性能和稳定性。
压缩列表
压缩列表的构成
压缩列表的构成
Redis中的压缩列表(ziplist)是一种紧凑的内存数据结构,主要用于存储多个简单的值,如字符串和整数。它是一种为了节省内存而设计的高效数据结构。压缩列表通过将多个元素紧凑地存储在一起,从而减少了内存开销。
1.1 压缩列表结构
压缩列表的整体结构包含以下几个部分:
- 头部:包含压缩列表的元数据,如总长度和节点数等。
- 节点:存储实际的数据,每个节点由多个字段组成,具体结构取决于节点的类型和编码方式。
- 尾部:标志压缩列表的结束。
1.2 头部
压缩列表的头部包含以下信息:
- 压缩列表的长度:包括头部、所有节点、尾部的总字节数。
- 节点数量:压缩列表中的节点数量。
- 最小节点长度:节点的最小长度(用于快速定位)。
- 最大节点长度:节点的最大长度(用于快速定位)。
1.3 节点
每个节点的结构由三个主要部分构成:
- previous_entry_length:前一个节点的长度。用于支持快速访问和遍历。
- Encoding:节点内容的编码方式。压缩列表支持多种编码方式,根据节点的实际内容选择合适的编码方式。
- Content:节点的实际内容。这部分存储节点的具体数据,可以是整数或字符串。
1.4 尾部
压缩列表的尾部是一个特殊的节点标记,标志着列表的结束。它的存在使得压缩列表可以高效地在尾部进行操作,如追加新的节点。
1.5 图示
以下是压缩列表的简化图示:
mermaid 复制代码 graph TD; A[Header] --> B[Node 1] B --> C[Node 2] C --> D[Node N] D --> E[Tail] - Header:压缩列表的头部,包括元数据。
- Node 1, Node 2, …, Node N:存储数据的节点,每个节点包含
previous_entry_length、Encoding和Content。 - Tail:压缩列表的尾部标记,指示列表的结束。
重点剖析
- 头部:
- 内存****布局:头部的大小在实现中是固定的,用于存储有关压缩列表的关键信息,确保可以快速定位和操作。
- 管理信息:头部的信息用于高效地访问和管理节点,支持快速插入、删除和遍历操作。
- 节点:
- previous_entry_length:这个字段允许在节点之间进行快速跳转,从而加速操作。例如,在删除节点时,可以通过这个字段快速找到前一个节点。
- Encoding:编码方式的选择对存储效率和操作性能有显著影响。合理的编码方式可以显著减少内存占用。例如,使用短编码来存储小整数或短字符串。
- Content:存储实际的数据,是压缩列表的核心内容。内容的格式可以根据编码方式变化,以适应不同的数据类型。
- 尾部:
- 结束标记:尾部的标记使得对压缩列表的操作更加高效,特别是在尾部进行插入操作时。
压缩列表的设计目的是在减少内存开销的同时,保持操作的高效性。它通过紧凑的内存布局和灵活的编码方式,实现了这一目标。
压缩列表节点的构成
在Redis的压缩列表(ziplist)中,每个节点(entry)由三个主要部分组成:previous_entry_length、Encoding 和 Content。这些字段共同决定了节点的存储方式和操作效率。以下是每个部分的详细分析:
2.1 previous_entry_length
- 定义:
previous_entry_length字段表示前一个节点的长度,用于支持快速的节点操作和双向遍历。 - 用途:
- 快速定位:在节点的插入、删除操作中,可以利用
previous_entry_length快速找到前一个节点,避免全列表遍历。 - 双向操作:支持从当前节点向前回溯,允许更灵活的数据操作。
- 快速定位:在节点的插入、删除操作中,可以利用
- 存储格式:
previous_entry_length的长度是可变的,根据前一个节点的实际长度决定。它通常使用可变长度的编码方式来存储。
示例
假设有一个压缩列表如下:
plaintext 复制代码 Header --> Node 1 --> Node 2 --> Node 3 --> Tail 如果Node 2的previous_entry_length是5字节,表示Node 1的长度是5字节。
2.2 Encoding
- 定义:
Encoding字段指示节点内容的编码方式。压缩列表支持多种编码方式,以提高存储效率。 - 用途:
- 节省****内存:通过选择合适的编码方式,可以减少节点的内存占用。例如,对于小整数,可以使用短编码方式。
- 提高性能:合适的编码方式可以优化数据存取的性能,减少数据解析和处理的开销。
- 编码方式:
- 整数编码:用于存储整数值,支持1字节、2字节或4字节的编码方式。
- 字符串编码:用于存储字符串,支持变长编码,根据字符串的长度进行编码。
示例
假设Node 1包含一个小整数42,编码方式为1字节编码:
plaintext 复制代码 Encoding: 0x00 (1-byte integer) Content: 42 (binary representation) 2.3 Content
- 定义:
Content字段包含节点的实际数据。它的格式取决于Encoding字段指定的编码方式。 - 用途:
- 存储数据:存储节点的实际内容,如整数值或字符串。
- 支持多种类型:根据编码方式,
Content可以存储不同类型的数据,如整数和字符串。
- 存储格式:
- 整数:如果节点存储的是整数,
Content字段将包含整数的二进制表示。 - 字符串:如果节点存储的是字符串,
Content字段将包含字符串的字节表示。
- 整数:如果节点存储的是整数,
示例
假设Node 2包含字符串“hello”,Content字段将存储字符串“hello”的字节表示:
Encoding: 0x01 (string) Content: 68 65 6c 6c 6f (hexadecimal for 'hello') - previous_entry_length:记录前一个节点的长度,支持高效的节点操作。
- Encoding:指定内容的编码方式,优化存储空间。
- Content:实际存储的数据,根据编码方式的不同可以是整数或字符串。
重点剖析
previous_entry_length:- 作用:提供快速的前向定位和操作支持,允许高效的节点管理和双向遍历。
- 存储:可变长度字段,存储前一个节点的长度,确保高效操作。
Encoding:- 作用:优化内存使用和性能。通过选择合适的编码方式,节省存储空间并提高访问效率。
- 类型:整数和字符串的编码方式根据实际数据类型和长度选择,提供灵活存储方案。
Content:- 作用:存储节点的实际数据,支持多种数据类型的存储。
- 格式:根据
Encoding字段,Content可以是整数或字符串的二进制表示。
连锁反应
在Redis的压缩列表(ziplist)中,“连锁反应”指的是对一个节点的操作如何影响到其他节点。这种现象主要体现在节点的插入、删除和移动操作中。由于压缩列表的结构和编码方式,节点之间的操作可能会引发连锁效应,影响列表的整体结构和性能。
3.1 插入操作
- 插入新节点:
- 影响:插入新节点会改变原有节点的结构,特别是在节点之间的“previous_entry_length”字段。新节点的插入可能会导致节点的重新定位和调整。
- 步骤:
- 节点插入:新节点被插入到目标位置。
- 调整长度:更新插入点前的节点的
previous_entry_length,以及后续节点的previous_entry_length。 - 重新计算头部信息:更新压缩列表的总长度和节点数量。
示例
假设在一个压缩列表中插入新节点:
Header --> Node 1 --> Node 2 --> Node 3 --> Tail 插入新节点Node 1.5:
Header --> Node 1 --> Node 1.5 --> Node 2 --> Node 3 --> Tail - 影响:
Node 1.5的previous_entry_length需要设置为Node 1的长度,Node 2的previous_entry_length需要更新为Node 1.5的长度。
3.2 删除操作
- 删除节点:
- 影响:删除节点会影响其前后节点的
previous_entry_length字段,可能导致列表结构的重新计算和调整。 - 步骤:
- 节点删除:从列表中移除指定节点。
- 调整长度:更新前一个节点的
previous_entry_length,以指向删除节点之后的节点。 - 更新头部信息:调整压缩列表的总长度和节点数量。
- 影响:删除节点会影响其前后节点的
示例
删除Node 2:
Header --> Node 1 --> Node 3 --> Tail - 影响:
Node 1的previous_entry_length需要更新为指向Node 3的长度。
3.3 移动操作
- 移动节点:
- 影响:节点的移动需要调整涉及节点的
previous_entry_length字段,并可能会导致节点的重新编码或重新排列。 - 步骤:
- 节点移动:将节点从一个位置移动到另一个位置。
- 调整引用:更新原位置和新位置的
previous_entry_length字段。 - 更新头部信息:调整压缩列表的总长度和节点数量。
- 影响:节点的移动需要调整涉及节点的
示例
将Node 3移动到Node 1和Node 2之间:
Header --> Node 1 --> Node 3 --> Node 2 --> Tail - 影响:
Node 1的previous_entry_length需要指向Node 3,Node 3的previous_entry_length需要指向Node 2。
重点剖析
连锁反应的复杂性:
- 影响:操作一个节点时,可能会影响其他多个节点,特别是节点之间的
previous_entry_length字段。 - 性能:频繁的节点操作(插入、删除、移动)会导致压缩列表的性能波动,需要高效地更新相关字段。
- 影响:操作一个节点时,可能会影响其他多个节点,特别是节点之间的
操作步骤:
- 插入:需要重新调整前后节点的
previous_entry_length,并更新列表的头部信息。 - 删除:需要重新调整前后节点的
previous_entry_length,并更新列表的头部信息。 - 移动:需要重新调整涉及节点的
previous_entry_length,并更新列表的头部信息。
- 插入:需要重新调整前后节点的
性能优化:
- 避免频繁操作:尽量减少对压缩列表的频繁插入、删除或移动操作,以降低性能开销。
- 高效更新:优化节点操作的实现,确保对相关字段的更新尽可能高效。
对象
对象的类型与编码
对象的类型
Redis对象的主要类型有五种,每种类型都有特定的功能和用例。下面是Redis对象类型的简要介绍:
字符串对象(String)
- 描述:最基本的数据类型,可以是任何二进制数据(包括文本)。字符串对象用于存储简单的键值对。
- 示例:
SET key "value"
列表对象(List)
- 描述:双向链表形式的数据结构。用于存储有序的字符串集合。
- 示例:
LPUSH list "value"
哈希对象(Hash)
- 描述:键值对的集合,适合用于存储对象。
- 示例:
HSET hash field "value"
集合对象(Set)
- 描述:无序的字符串集合,不允许重复元素。适合用于存储唯一的值。
- 示例:
SADD set "value"
有序集合对象(Sorted Set)
- 描述:类似于集合,但每个元素都会关联一个分数。元素按照分数进行排序。
- 示例:
ZADD zset score "value"
图示:Redis对象类型
字符串对象(String)
编码方式:
- RAW:原始字符串编码,用于存储纯文本或二进制数据。
- INT:整型编码,当字符串可以被解释为整数时,使用整数编码来节省内存。
- EMBSTR:嵌入式字符串编码,适用于短字符串,将字符串直接嵌入
redisObject结构体中。
实现:
- RAW:
- 使用
SDS(Simple Dynamic String)库来动态管理字符串的内存分配。 SDS提供了动态调整字符串长度的功能,避免频繁的内存分配和释放。
- 使用
// sds结构体示例 typedef struct sdshdr { unsigned int len; // 字符串长度 unsigned int free; // 可用内存 char buf[]; // 存储实际数据 } SDS; - INT:
- 字符串被转换为整数值存储,节省内存。
- EMBSTR:
- 短字符串直接嵌入
redisObject结构体中,不需要额外的内存分配。
- 短字符串直接嵌入
// redisObject结构体示例 typedef struct redisObject { unsigned type:4; // 对象类型 unsigned encoding:4; // 编码方式 unsigned refcount:16; // 引用计数 void *ptr; // 指向实际数据 } RedisObject; 编码转换
- RAW 到 EMBSTR
- 条件:当字符串长度较短(通常在 39字节以内)时,Redis 可以将
RAW编码转换为EMBSTR编码,以节省内存。 - 转换步骤:
- 判断字符串长度是否符合
EMBSTR的条件。 - 将
RAW编码的字符串直接嵌入redisObject结构体中。
- 判断字符串长度是否符合
- 条件:当字符串长度较短(通常在 39字节以内)时,Redis 可以将
- EMBSTR 到 RAW
- 条件:当字符串长度超过
EMBSTR的限制时,Redis 会将EMBSTR编码转换回RAW编码。 - 转换步骤:
- 创建新的
RAW编码对象。 - 复制
EMBSTR中的字符串内容到新的RAW编码对象中。
- 创建新的
- 条件:当字符串长度超过
- RAW 到 INT
- 条件:当字符串可以被解释为整数时,Redis 会将
RAW编码的字符串转换为INT编码。 - 转换步骤:
- 尝试将
RAW编码的字符串解析为整数。 - 如果解析成功,创建
INT编码的对象并存储整数值。
- 尝试将
- 条件:当字符串可以被解释为整数时,Redis 会将
- INT 到 RAW
- 条件:当整数被转换为
RAW编码时,Redis 将整数值转换为字符串格式。 - 转换步骤:
- 将
INT编码的整数转换为字符串。 - 创建
RAW编码的对象并存储字符串内容。
- 将
- 条件:当整数被转换为
字符串命令的实现
SET
- 功能:设置指定键的值。
- 实现:
- 判断值的类型并选择合适的编码方式(
RAW、EMBSTR或INT)。 - 将值存储在键对应的对象中。
- 判断值的类型并选择合适的编码方式(
GET
- 功能:获取指定键的值。
- 实现:
- 查找键对应的对象。
- 根据对象的编码方式,返回相应的值(处理
RAW、EMBSTR和INT编码)。
列表对象(List)
编码方式:
- ZIPLIST:压缩列表,用于存储小型列表,以节省内存。
- LINKEDLIST:链表,用于存储较大的列表,支持高效的插入和删除操作。
实现:
- ZIPLIST:
- 使用压缩的格式来存储列表元素,减少内存碎片。
- 通过将多个元素存储在一个连续的内存块中来节省空间。
// ziplist结构体示例 typedef struct { unsigned char *zl; // 指向压缩列表的指针 unsigned int size; // 列表大小 } Ziplist; - LINKEDLIST:
- 实现为双向链表,每个节点包含一个元素和指向前后节点的指针。
- 支持高效的插入、删除和访问操作。
// listNode结构体示例 typedef struct listNode { void *value; // 节点存储的值 struct listNode *prev; // 指向前一个节点的指针 struct listNode *next; // 指向下一个节点的指针 } listNode; - 图示:

- ZIPLIST:存储在一个压缩的内存块中,适合小型列表。
- LINKEDLIST:双向链表结构,适合大型列表。
编码转换
- ZIPLIST 到 LINKEDLIST
- 条件:当列表中的元素数量较多或操作频繁时,Redis 会将
ZIPLIST编码的列表转换为LINKEDLIST编码,以提高操作性能。 - 转换步骤:
- 遍历
ZIPLIST中的所有元素。 - 将每个元素插入到
LINKEDLIST中。 - 更新列表对象的编码方式为
LINKEDLIST。
- 遍历
- 条件:当列表中的元素数量较多或操作频繁时,Redis 会将
- LINKEDLIST 到 ZIPLIST
- 条件:当
LINKEDLIST编码的列表变得较小且操作频率降低时,Redis 会将其转换为ZIPLIST编码以节省内存。 - 转换步骤:
- 遍历
LINKEDLIST中的所有元素。 - 将每个元素存储到
ZIPLIST中。 - 更新列表对象的编码方式为
ZIPLIST。
- 遍历
- 条件:当
列表命令的实现
LPUSH / RPUSH
- 功能:在列表的左侧或右侧推入一个或多个值。
- 实现:
- 判断当前列表的编码方式(
ZIPLIST或LINKEDLIST)。 - 根据编码方式将元素插入到列表的相应位置。
- 在需要时进行编码转换。
- 判断当前列表的编码方式(
LPOP / RPOP
- 功能:从列表的左侧或右侧弹出一个值。
- 实现:
- 查找列表的编码方式(
ZIPLIST或LINKEDLIST)。 - 根据编码方式从列表中移除并返回相应的元素。
- 在需要时进行编码转换。
- 查找列表的编码方式(
LRANGE
- 功能:返回列表中指定范围的元素。
- 实现:
- 根据列表的编码方式(
ZIPLIST或LINKEDLIST)检索指定范围的元素。 - 如果是
ZIPLIST,使用压缩列表的索引进行检索。 - 如果是
LINKEDLIST,遍历链表并收集结果。
- 根据列表的编码方式(
哈希对象(Hash)
编码方式:
- ZIPLIST:用于存储小型哈希,所有字段和对应值都存储在一个压缩列表中。
- HT**(哈希表)**:用于存储大型哈希,基于开放地址法的哈希表实现。
实现:
- ZIPLIST:
- 将哈希的所有字段和对应的值存储在一个连续的压缩列表中。
- 适合字段和值都较小的哈希对象,节省内存并减少内存碎片。
// ziplist结构体示例 typedef struct { unsigned char *zl; // 指向压缩列表的指针 unsigned int size; // 哈希大小 } Ziplist; - HT**(哈希表)**:
- 基于开放地址法的哈希表实现,用于存储大型哈希对象。
- 使用哈希函数将字段映射到桶中,支持高效的查找和插入操作。
// dictEntry结构体示例 typedef struct dictEntry { void *key; // 哈希表中的键 void *val; // 键对应的值 } dictEntry; typedef struct dict { dictEntry **table; // 哈希表数组 unsigned int size; // 哈希表大小 } dict; - 图示:
- ZIPLIST:用于存储小型哈希对象,字段和值存储在一个压缩列表中。
- HT**(哈希表)**:用于存储大型哈希对象,基于哈希函数映射到桶中。
编码转换
- ZIPLIST 到HT
- 条件:当哈希中的字段数量增加到一定阈值,Redis 会将
ZIPLIST编码的哈希转换为HT编码,以提高查找和操作性能。 - 转换步骤:
- 遍历
ZIPLIST中的所有字段和值。 - 将每个字段和值插入到
HT哈希表中。 - 更新哈希对象的编码方式为
HT。
- 遍历
- 条件:当哈希中的字段数量增加到一定阈值,Redis 会将
- HT到 ZIPLIST
- 条件:当
HT编码的哈希变得较小且字段数量减少时,Redis 会将其转换为ZIPLIST编码以节省内存。 - 转换步骤:
- 遍历
HT哈希表中的所有字段和值。 - 将每个字段和值存储到
ZIPLIST中。 - 更新哈希对象的编码方式为
ZIPLIST。
- 遍历
- 条件:当
哈希命令的实现
HSET
- 功能:设置哈希表中字段的值。
- 实现:
- 判断哈希对象的编码方式(
ZIPLIST或HT)。 - 根据编码方式更新字段的值。
- 如果需要,进行编码转换。
- 判断哈希对象的编码方式(
HGET
- 功能:获取哈希表中字段的值。
- 实现:
- 查找哈希对象的编码方式(
ZIPLIST或HT)。 - 根据编码方式获取字段的值。
- 如果需要,进行编码转换。
- 查找哈希对象的编码方式(
HDEL
- 功能:删除哈希表中指定字段。
- 实现:
- 查找哈希对象的编码方式(
ZIPLIST或HT)。 - 根据编码方式从哈希表中删除字段。
- 如果需要,进行编码转换。
- 查找哈希对象的编码方式(
HGETALL
- 功能:获取哈希表中所有字段和值。
- 实现:
- 根据哈希对象的编码方式(
ZIPLIST或HT)遍历所有字段和值。 - 如果是
ZIPLIST,使用压缩列表的索引进行遍历。 - 如果是
HT,直接遍历哈希表中的所有条目。
- 根据哈希对象的编码方式(
集合对象(Set)
编码方式:
- INTSET:用于存储小型集合,其中所有元素都是整数。
- HT**(哈希表)**:用于存储大型集合,基于哈希表的实现。
实现:
- INTSET:
- 使用紧凑的整数数组来存储集合中的元素。
- 适合集合中元素较少且所有元素为整数的情况。
- 随着元素数量的增加,
INTSET可以动态调整其存储的整数类型(如从8位整数到16位整数等)。
// intset结构体示例 typedef struct intset { uint32_t encoding; // 存储元素的编码方式(如 8位、16位、32位等) uint32_t length; // 集合中的元素数量 int8_t contents[]; // 存储元素的数组 } intset; - HT**(哈希表)**:
- 采用哈希表来处理较大的集合,支持高效的成员查询和插入。
- 使用哈希函数将元素映射到桶中,避免了使用链表带来的高内存消耗。
// dictEntry结构体示例 typedef struct dictEntry { void *key; // 哈希表中的键(集合元素) void *val; // 对应的值(在集合中通常不使用) } dictEntry; typedef struct dict { dictEntry **table; // 哈希表数组 unsigned int size; // 哈希表大小 } dict; - 图示:
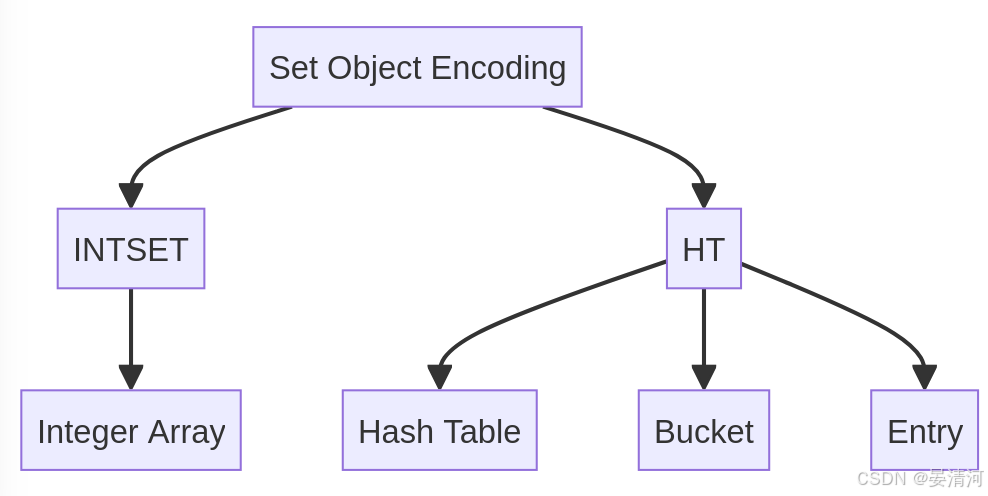
- INTSET:使用紧凑的整数数组,适合小型集合。
- HT**(哈希表)**:使用哈希表,适合大型集合,支持高效的成员查询。
编码转换
- INTSET 到HT
- 条件:当集合的元素数量增多或元素类型发生变化(例如,从整数集合到包含其他类型的集合),Redis 会将
INTSET编码的集合转换为HT编码,以提高操作性能。 - 转换步骤:
- 遍历
INTSET中的所有整数元素。 - 将每个元素插入到
HT哈希表中。 - 更新集合对象的编码方式为
HT。
- 遍历
- 条件:当集合的元素数量增多或元素类型发生变化(例如,从整数集合到包含其他类型的集合),Redis 会将
- HT到 INTSET
- 条件:当
HT编码的集合元素数量减少且所有元素为整数时,Redis 会将其转换为INTSET编码以节省内存。 - 转换步骤:
- 遍历
HT哈希表中的所有元素。 - 将每个整数元素存储到
INTSET中。 - 更新集合对象的编码方式为
INTSET。
- 遍历
- 条件:当
集合命令的实现
SADD
- 功能:将一个或多个成员添加到集合中。
- 实现:
- 判断集合的编码方式(
INTSET或HT)。 - 根据编码方式添加新成员。
- 如果需要,进行编码转换。
- 判断集合的编码方式(
SREM
- 功能:从集合中删除一个或多个成员。
- 实现:
- 查找集合的编码方式(
INTSET或HT)。 - 根据编码方式从集合中删除成员。
- 如果需要,进行编码转换。
- 查找集合的编码方式(
SMEMBERS
- 功能:返回集合中的所有成员。
- 实现:
- 根据集合的编码方式(
INTSET或HT)遍历所有成员。 - 如果是
INTSET,直接遍历整数数组。 - 如果是
HT,遍历哈希表中的所有条目。
- 根据集合的编码方式(
SISMEMBER
- 功能:检查指定成员是否存在于集合中。
- 实现:
- 查找集合的编码方式(
INTSET或HT)。 - 根据编码方式检查成员的存在性。
- 如果需要,进行编码转换
- 查找集合的编码方式(
有序集合对象(Sorted Set)
编码方式:
- ZIPLIST:用于存储小型有序集合,元素按分数排序存储在压缩列表中。
- SKIPLIST:跳表,用于存储大型有序集合,以支持高效的范围查询和排序操作。
实现:
- ZIPLIST:
- 适合存储较小的有序集合,使用压缩列表来存储每个元素及其分数。
- 元素和分数以紧凑的格式存储在一个连续的内存块中。
// ziplist结构体示例 typedef struct { unsigned char *zl; // 指向压缩列表的指针 unsigned int size; // 有序集合的大小 } Ziplist; - SKIPLIST:
- 实现为多级链表结构,每一层是一个有序的链表。
- 通过跳跃表的结构,提供对元素的高效插入、删除和范围查询操作。
// skiplistNode结构体示例 typedef struct zskiplistNode { void *obj; // 有序集合的元素 double score; // 元素的分数 struct zskiplistNode *forward; // 跳表的下一层节点 } zskiplistNode; typedef struct zskiplist { zskiplistNode *header; // 跳表的头节点 int level; // 跳表的层数 } zskiplist; - 图示:
- ZIPLIST:适用于小型有序集合,元素和分数存储在压缩列表中。
- SKIPLIST:多级链表结构,适合大型有序集合,支持高效的范围查询和排序操作。
编码转换
- ZIPLIST 到 SKIPLIST
- 条件:当有序集合中的元素数量增加,Redis 会将
ZIPLIST编码的有序集合转换为SKIPLIST编码,以支持高效的范围查询和排序操作。 - 转换步骤:
- 遍历
ZIPLIST中的所有元素及其分数。 - 将每个元素及其分数插入到
SKIPLIST中。 - 更新有序集合对象的编码方式为
SKIPLIST。
- 遍历
- 条件:当有序集合中的元素数量增加,Redis 会将
- SKIPLIST 到 ZIPLIST
- 条件:当
SKIPLIST编码的有序集合变得较小且操作频率降低时,Redis 会将其转换为ZIPLIST编码以节省内存。 - 转换步骤:
- 遍历
SKIPLIST中的所有元素及其分数。 - 将每个元素及其分数存储到
ZIPLIST中。 - 更新有序集合对象的编码方式为
ZIPLIST。
- 遍历
- 条件:当
有序集合命令的实现
- ZADD
- 功能:向有序集合中添加一个或多个元素及其分数。
- 实现:
- 判断有序集合的编码方式(
ZIPLIST或SKIPLIST)。 - 根据编码方式添加新元素和分数。
- 如果需要,进行编码转换。
- 判断有序集合的编码方式(
- ZRANGE
- 功能:返回有序集合中指定范围内的元素。
- 实现:
- 根据有序集合的编码方式(
ZIPLIST或SKIPLIST)进行范围查询。 - 如果是
ZIPLIST,使用压缩列表的索引进行查询。 - 如果是
SKIPLIST,遍历跳表中的节点进行查询。
- 根据有序集合的编码方式(
- ZREM
- 功能:从有序集合中删除一个或多个元素。
- 实现:
- 查找有序集合的编码方式(
ZIPLIST或SKIPLIST)。 - 根据编码方式删除元素。
- 如果需要,进行编码转换。
- 查找有序集合的编码方式(
- ZSCORE
- 功能:获取有序集合中指定元素的分数。
- 实现:
- 查找有序集合的编码方式(
ZIPLIST或SKIPLIST)。 - 根据编码方式获取元素的分数。
- 如果需要,进行编码转换。
- 查找有序集合的编码方式(
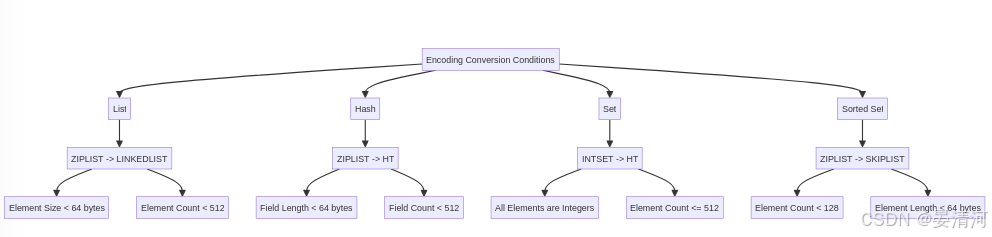
总结:转换条件
列表对象(List)
- 压缩列表到****链表:
- 每个元素大小:小于 64 字节
- 元素数量:小于 512
- 当列表的元素数量增加或元素大小变大时,Redis 将压缩列表(ZIPLIST)转换为链表(LINKEDLIST),以支持高效的插入和删除操作。
哈希对象(Hash)
- 压缩列表到****哈希表:
- 字段长度:小于 64 字节
- 字段数量:小于 512
- 当哈希的字段数量增加或字段长度变长时,Redis 将压缩列表(ZIPLIST)转换为哈希表(HT),以支持高效的查找和操作。
集合对象(Set)
- 整数集合到****哈希表:
- 所有元素:都是整数
- 元素数量:不能超过 512
- 当集合的元素数量增加或元素不是整数时,Redis 将整数集合(INTSET)转换为哈希表(HT),以支持更大的集合和多种数据类型。
有序集合对象(Sorted Set)
- 压缩列表到跳表:
- 元素数量:小于 128
- 元素长度:每个长度不能超过 64 字节
- 当有序集合的元素数量增加或元素长度变长时,Redis 将压缩列表(ZIPLIST)转换为跳表(SKIPLIST),以支持高效的范围查询和排序操作。
类型检查与命令多态
类型检查的实现
Redis 在处理不同类型的对象时,需要确保操作的正确性。为此,Redis 实现了类型检查机制来验证对象的类型。
- 类型检查的实现步骤:
- 数据结构:每个 Redis 对象都有一个
type字段,用于表示对象的类型。 - 操作前检查:
- 对象类型检查:在执行命令之前,Redis 会检查对象的类型是否与命令要求的类型匹配。例如,如果一个命令要求操作字符串对象,那么 Redis 会检查对象的
type是否为REDIS_STRING。 - 错误处理:如果对象的类型不匹配,Redis 会返回错误信息,告知用户操作不合法。
- 对象类型检查:在执行命令之前,Redis 会检查对象的类型是否与命令要求的类型匹配。例如,如果一个命令要求操作字符串对象,那么 Redis 会检查对象的
- 数据结构:每个 Redis 对象都有一个
- 示例代码:
// 检查对象类型的宏 #define OBJ_TYPE_CHECK(obj, type) \ if ((obj)->type != (type)) return NULL; // 返回错误或处理逻辑 // 示例:检查一个对象是否是字符串类型 void handleStringCommand(robj *obj) { OBJ_TYPE_CHECK(obj, REDIS_STRING); // 继续处理字符串对象的命令 } 多态命令的实现
Redis 支持命令的多态性,使得相同的命令可以操作不同类型的对象。这是通过以下机制实现的:
- 多态命令实现步骤:
- 命令分发:每个命令在执行时,根据对象的类型调用不同的处理函数。例如,
GET命令对字符串对象和哈希对象的处理逻辑是不同的。 - 函数指针:Redis 使用函数指针来实现多态命令。每种对象类型都有一个对应的处理函数,当命令执行时,Redis 会根据对象的实际类型调用相应的函数。
- 命令分发:每个命令在执行时,根据对象的类型调用不同的处理函数。例如,
- 示例代码:
// 函数指针定义 typedef void (*commandHandler)(robj *obj); // 字符串类型的命令处理函数 void handleStringCommand(robj *obj) { // 处理字符串类型对象的命令 } // 哈希类型的命令处理函数 void handleHashCommand(robj *obj) { // 处理哈希类型对象的命令 } // 根据对象类型选择处理函数 void processCommand(robj *obj, commandHandler handler) { handler(obj); } // 示例:处理命令 void executeCommand(robj *obj) { if (obj->type == REDIS_STRING) { processCommand(obj, handleStringCommand); } else if (obj->type == REDIS_HASH) { processCommand(obj, handleHashCommand); } // 其他类型处理 } - 图示:
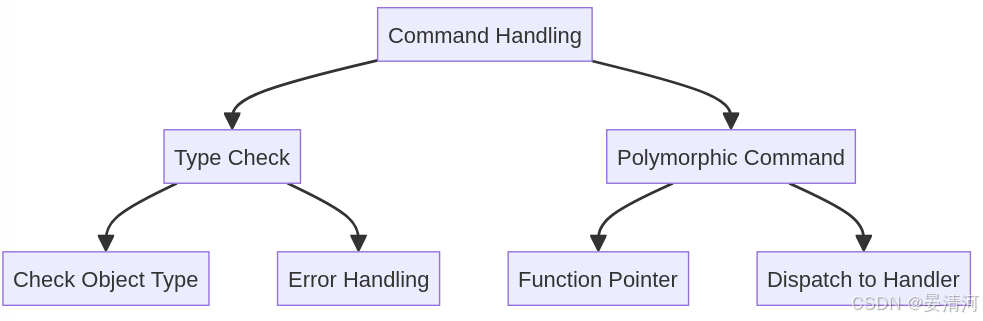
- 检查:通过检查对象的
type字段来确保操作的正确性。 - 多态命令:使用函数指针和类型检查来动态调用适当的命令处理函数。
内存回收
。
内存回收
在 Redis 中,内存回收是一个重要的机制,用于管理和优化内存的使用,确保系统的稳定性和性能。Redis 的内存回收涉及到对象的生命周期管理和内存的释放。
内存回收的实现
对象的生命周期管理
- 引用计数:Redis 使用引用计数来跟踪对象的引用数量。每个对象都有一个引用计数器,当对象被引用时,计数器增加;当引用被释放时,计数器减少。对象的内存只有在引用计数降为零时才会被回收。
- 示例代码:
// 创建一个新对象并初始化引用计数 robj *createObject(int type, void *ptr) { robj *o = zmalloc(sizeof(robj)); o->type = type; o->ptr = ptr; o->refcount = 1; // 初始引用计数为 1 return o; } // 增加对象的引用计数 void incrRefCount(robj *o) { o->refcount++; } // 减少对象的引用计数并在需要时回收内存 void decrRefCount(robj *o) { if (--o->refcount == 0) { // 释放对象的内存 // 假设释放内存的函数是 freeObject freeObject(o); } } 垃圾回收****策略
- 延迟回收:Redis 使用延迟回收策略,通过周期性检查和释放不再使用的对象内存来减少内存碎片。这种策略避免了频繁的内存分配和释放带来的性能开销。
- 示例代码:
// 释放对象的内存 void freeObject(robj *o) { if (o->type == REDIS_STRING) { sdsfree(o->ptr); // 释放字符串对象的内存 } else if (o->type == REDIS_LIST) { // 释放列表对象的内存 } else if (o->type == REDIS_HASH) { // 释放哈希对象的内存 } // 其他对象类型的处理 zfree(o); // 释放对象结构体本身的内存 } 内存****释放
- 内存****释放函数:当对象的引用计数降为零时,Redis 会调用内存释放函数释放对象占用的内存。
- 示例代码:
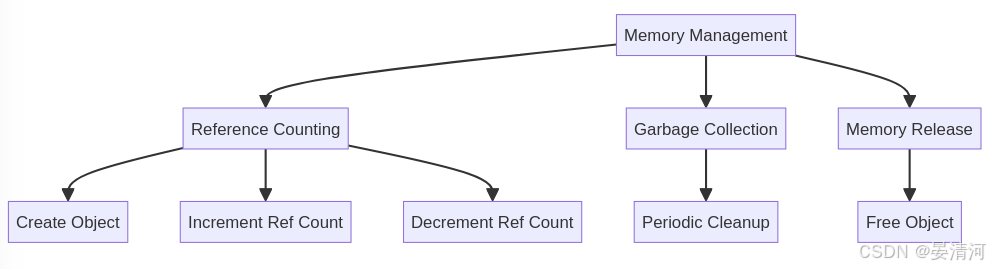
- 内存****回收:
- 引用计数:用于跟踪对象的引用并在引用计数为零时回收内存。
- 垃圾回收:定期清理不再使用的对象。
- 内存****释放:调用释放函数释放对象的内存。
对象共享
Redis 使用对象共享机制来优化内存使用和提高性能。对象共享的核心思想是避免重复创建相同内容的对象,从而减少内存消耗和提升操作效率。
对象共享的实现
- 共享对象的概念
- 共享对象:Redis 通过引用相同的对象实例来实现对象共享。例如,多个键可以指向同一个值对象,避免了相同数据的重复存储。
- 共享策略:共享机制主要应用于字符串、列表、哈希等数据类型。对于不可变的数据类型,如字符串常量,Redis 可以直接共享它们。
- 共享对象的实现步骤
- 对象创建:
- Redis 在创建对象时会首先检查是否已有相同内容的对象存在。如果存在,则复用已有对象,而不是创建新对象。
- 对象查找:
- Redis 使用全局的哈希表来管理共享的对象。这个哈希表存储了所有共享对象的引用。对象的查找和复用主要依赖于这个哈希表。
- 示例代码:
-
// 创建并共享对象 robj *createSharedObject(int type, void *ptr) { // 使用全局哈希表查找是否已有相同对象 robj *sharedObj = findSharedObject(ptr); if (sharedObj != NULL) { return sharedObj; // 返回已存在的共享对象 } // 创建新对象并将其添加到共享哈希表 robj *newObj = createObject(type, ptr); addObjectToSharedTable(newObj); return newObj; } // 查找共享对象 robj *findSharedObject(void *ptr) { // 查找共享对象哈希表 // 返回对应的共享对象或 NULL } // 将对象添加到共享哈希表 void addObjectToSharedTable(robj *obj) { // 将对象添加到全局共享哈希表 }
- 对象创建:
- 共享对象的类型
字符串共享:
- Redis 对于相同的字符串内容进行共享,尤其是对短小字符串(如“OK”)进行优化,避免重复创建相同的字符串对象。
示例代码:
-
// 共享常量字符串 robj *sharedOK = createSharedObject(REDIS_STRING, "OK"); 列表、哈希等:
- 对于较复杂的数据结构,如列表和哈希,Redis 也会尝试进行对象共享,但需要确保对象的内容一致。
- 图示:

bm1kXzE3MjI5MzEzNDU6MTcyMjkzNDk0NV9WNA&pos_id=img-smWRaSUD-1722931509615)
- 对象共享:
- 共享对象:通过复用已有对象来减少内存消耗。
- 对象查找:使用全局哈希表来管理和查找共享对象。
- 共享策略:主要用于字符串和其他不可变数据类型。
对象的空转时长
对象的空转时长(Idle Time)指的是对象在 Redis 中未被访问或操作的时间长度。Redis 使用这个概念来管理和回收长期不活动的对象,从而优化内存使用和性能。
对象空转时长的实现
- 空转时长的记录
- 时间戳:Redis 为每个对象记录一个时间戳,表示该对象最后一次被访问的时间。这是通过系统时间来实现的。
- 示例代码:
-
// 更新对象的空转时间 void updateObjectIdleTime(robj *obj) { obj->last_access_time = getCurrentTime(); // 获取当前时间 } // 获取当前系统时间 time_t getCurrentTime() { return time(NULL); // 返回当前时间戳 }
- 对象空转回收
- 空转回收机制:Redis 定期检查对象的空转时长,如果某个对象的空转时长超过了设定的阈值,则会将其标记为可回收或直接回收。
- 回收策略:
- 惰性删除:只有在对象被访问时,Redis 才检查其空转时长,如果超出阈值则进行删除。
- 定期回收:Redis 定期运行清理任务,遍历所有对象并删除超出空转时长的对象。
- 示例代码:
-
// 清理超时对象的函数 void periodicCleanup() { time_t now = getCurrentTime(); // 遍历所有对象 for (each object in all_objects) { if (now - object->last_access_time > IDLE_TIMEOUT) { freeObject(object); // 释放超时对象的内存 } } } // 空转超时时长阈值 #define IDLE_TIMEOUT 3600 // 1 小时
- 配置和管理
- 配置参数:Redis 提供了配置参数来调整对象空转的回收策略。例如,可以设置空转时长阈值和定期回收的频率。
- 配置示例:
-
# Redis 配置文件示例 # 设置对象的空转时长阈值为 1 小时 idle_timeout 3600
- 图示:

- 空转时长管理:
- 记录空转时间:为每个对象记录最后访问时间。
- 回收机制:通过惰性删除和定期清理来回收长期不活动的对象。
- 配置管理:通过配置文件调整空转时长和清理频率。