吴恩达机器学习C1W2Lab05-使用Scikit-Learn进行线性回归
创始人
2024-11-13 05:37:46
前言
有一个开源的、商业上可用的机器学习工具包,叫做scikit-learn。这个工具包包含了你将在本课程中使用的许多算法的实现。
目标
在本实验中,你将:
- 利用scikit-learn实现使用梯度下降的线性回归
工具
您将使用scikit-learn中的函数以及matplotlib和NumPy。
import numpy as np np.set_printoptions(precision=2) from sklearn.linear_model import LinearRegression, SGDRegressor from sklearn.preprocessing import StandardScaler from lab_utils_multi import load_house_data import matplotlib.pyplot as plt dlblue = '#0096ff'; dlorange = '#FF9300'; dldarkred='#C00000'; dlmagenta='#FF40FF'; dlpurple='#7030A0'; plt.style.use('./deeplearning.mplstyle') 注意点
可能会出现报错 No module named ‘sklearn’
这是因为当前环境下未安装scikit-learn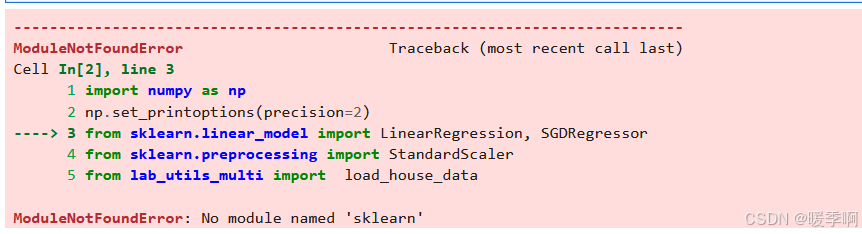 【解决办法】:在cmd中输入
【解决办法】:在cmd中输入
pip install scikit-learn 梯度下降
Scikit-learn有一个梯度下降回归模型sklearn.linear_model.SGDRegressor。与之前的梯度下降实现一样,该模型在规范化输入时表现最好。standardscaler将像之前的实验一样执行z-score归一化。这里它被称为“标准分数”。
加载数据集
X_train, y_train = load_house_data() X_features = ['size(sqft)','bedrooms','floors','age'] 缩放/规范化训练数据
scaler = StandardScaler() X_norm = scaler.fit_transform(X_train) print(f"Peak to Peak range by column in Raw X:{np.ptp(X_train,axis=0)}") print(f"Peak to Peak range by column in Normalized X:{np.ptp(X_norm,axis=0)}") 创建并拟合回归模型
sgdr = SGDRegressor(max_iter=1000) sgdr.fit(X_norm, y_train) print(sgdr) print(f"number of iterations completed: {sgdr.n_iter_}, number of weight updates: {sgdr.t_}") 视图参数
注意,参数与规范化的输入数据相关联。拟合参数与之前使用该数据的实验室中发现的非常接近。
b_norm = sgdr.intercept_ w_norm = sgdr.coef_ print(f"model parameters: w: {w_norm}, b:{b_norm}") print(f"model parameters from previous lab: w: [110.56 -21.27 -32.71 -37.97], b: 363.16") 做出预测
预测训练数据的目标。使用’ predict '例程并使用 w w w和 b b b进行计算。
# make a prediction using sgdr.predict() y_pred_sgd = sgdr.predict(X_norm) # make a prediction using w,b. y_pred = np.dot(X_norm, w_norm) + b_norm print(f"prediction using np.dot() and sgdr.predict match: {(y_pred == y_pred_sgd).all()}") print(f"Prediction on training set:\n{y_pred[:4]}" ) print(f"Target values \n{y_train[:4]}") 绘制结果
让我们绘制预测值与目标值的对比图。
# plot predictions and targets vs original features fig,ax=plt.subplots(1,4,figsize=(12,3),sharey=True) for i in range(len(ax)): ax[i].scatter(X_train[:,i],y_train, label = 'target') ax[i].set_xlabel(X_features[i]) ax[i].scatter(X_train[:,i],y_pred,color=dlorange, label = 'predict') ax[0].set_ylabel("Price"); ax[0].legend(); fig.suptitle("target versus prediction using z-score normalized model") plt.show() 祝贺
在这个实验中,你:
-使用开源机器学习工具包scikit-learn
-实现线性回归使用梯度下降和特征归一化的工具包
相关内容
热门资讯
裸辞做“一人公司”,我后悔了
去年这个时候,一位以色列程序员正在东南亚旅行。他顺手把一个在脑子里转了很久的想法做成了产品,一个让任...
南京建成国内首个Pre-6G试...
4月21日,2026全球6G技术与产业生态大会在南京开幕。全息互动技术展台前,一名远在北京的工作人员...
超梵求职受邀参加“2025抖音...
超梵求职受邀参加“2025抖音巨量引擎成人教育行业生态大会”,探讨分享优质内容传播,服务万千学员。 ...
摩托罗拉Razr 2026(R...
IT之家 4 月 22 日消息,摩托罗拉宣布新一代 Razr 折叠手机将于 4 月 29 日在美国发...
库克卸任,特纳斯领航:苹果新纪...
苹果首席执行官蒂姆·库克将卸任,硬件工程主管约翰·特纳斯将接任,苹果公司今天宣布此事。 库克将在夏季...