达梦数据库系列—44.SQL调优
目录
SQL优化思路
1、定位慢sql
2、SQL分析方法
2.1 执行计划
2.2 ET 工具
2.3 dbms_sqltune 工具
3、SQL语句优化
3.1 索引
3.2 SQL语句改写
3.3 表设计优化
3.4 表的连接方式
3.5 HINT
4、统计信息
SQL优化思路
1、定位慢sql
待优化的SQL大致可分为两类:
1、SQL 执行时间在十几秒到数十秒之间,但执行频率不高,此类 SQL 对数据库整体性能影响并不大,可以放到最后进行优化。
2、SQL 单独执行时间可能很快,在几百毫秒到几秒之间,但执行频率非常高,甚至达到每秒上百次,高并发下执行效率降低,很可能导致系统瘫痪,此类 SQL 是优化的首要对象。
定位慢sql的两种方法:
- 开启跟踪日志,见“日志总结-SQL日志”
- 通过系统视图查看,见“常用SQL-sql相关”
2、SQL分析方法
2.1 执行计划
见达梦数据库系列-40.执行计划
2.2 ET 工具
ET 功能默认关闭,可通过配置 INI 参数中的 ENABLE_MONITOR=1、MONITOR_SQL_EXEC=1 开启该功能。
--两个参数均为动态参数,可直接调用系统函数进行修改
SP_SET_PARA_VALUE(1,'ENABLE_MONITOR',1);
SP_SET_PARA_VALUE(1,'MONITOR_SQL_EXEC',1);
--会话级别修改只在当前会话生效
SF_SET_SESSION_PARA_VALUE('MONITOR_SQL_EXEC',1);
--关闭 ET
SP_SET_PARA_VALUE(1,'ENABLE_MONITOR',0);
SP_SET_PARA_VALUE(1,'MONITOR_SQL_EXEC',0);
执行 SQL 语句后,客户端会返回 SQL 语句的执行号。单击执行号即可查看 SQL 语句对应的 ET 结果。

如果没有图形界面,调用存储过程可返回相同结果。
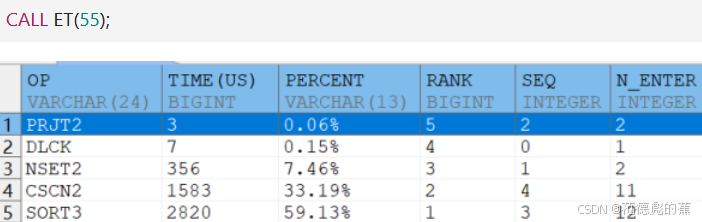
- OP: 操作符
- TIME(us): 时间开销,单位为微秒
- PERCENT: 执行时间占总时间百分比
- RANK: 执行时间耗时排序
- SEQ: 执行计划节点号
- N_ENTER: 进入次数
2.3 dbms_sqltune 工具
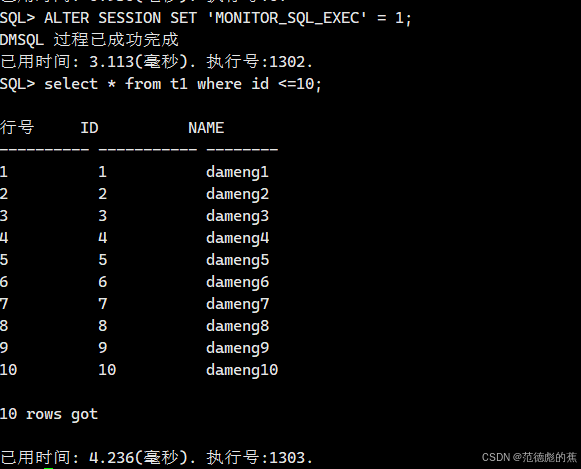
使用前提:建议会话级开启参数 MONITOR_SQL_EXEC=1
ALTER SESSION SET 'MONITOR_SQL_EXEC' = 1;
<执行待优化SQL>
select DBMS_SQLTUNE.REPORT_SQL_MONITOR(SQL_EXEC_ID=>1213701) from dual;
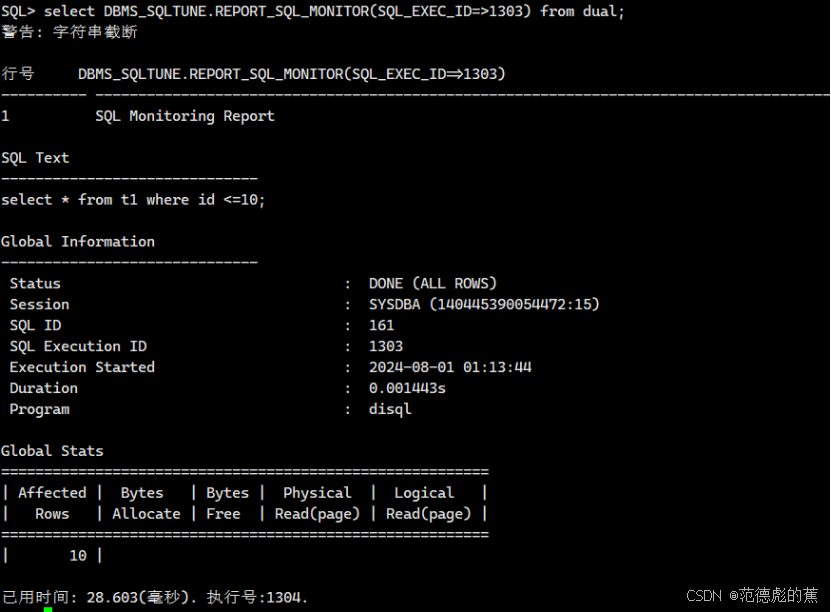
3、SQL语句优化
3.1 索引
索引存储结构

从B*树中访问每个叶子节点的成本都是h次IO,索引的访问效率只跟B*树的高度有关系。
以下场景可考虑创建索引:
- 仅当要通过索引访问表中很少的一部分行(1%~20%)。
- 索引可覆盖查询所需的所有列,不需额外去访问表。
组合索引的顺序:
- 最优先把等值匹配的列放最前面,范围匹配的放后面
- 其次把过滤性好的列放前面,过滤性差的放后面
- 查询时组合索引只能利用一个非等值字段
存在下列情况将导致无法使用索引:
- 条件列不是索引的首列
- 条件列上有函数或计算
- 存在隐式类型转换
- 如果走索引会更慢
建立索引的原则:
- 建立唯一索引。唯一索引能够更快速地帮助我们进行数据定位;
- 为经常需要进行查询操作的字段建立索引;
- 对经常需要进行排序、分组以及联合操作的字段建立索引;
- 在建立索引的时候,要考虑索引的最左匹配原则(在使用 SQL 语句时,如果 where 部分的条件不符合最左匹配原则,可能导致索引失效,或者不能完全发挥建立的索引的功效);
- 不要建立过多的索引。因为索引本身会占用存储空间;
- 如果建立的单个索引查询数据很多,查询得到的数据的区分度不大,则考虑建立合适的联合索引;
- 尽量考虑字段值长度较短的字段建立索引,如果字段值太长,会降低索引的效率。
3.2 SQL语句改写
优化 GROUP BY
在 GROUP BY 之前过滤掉不需要的内容
--优化前
SELECT JOB,AVG(AGE) FROM TEMP GROUP BY JOB HAVING JOB = 'STUDENT' OR JOB = 'MANAGER';
--优化后
SELECT JOB,AVG(AGE) FROM TEMP WHERE JOB = 'STUDENT' OR JOB = 'MANAGER' GROUP BY JOB;
用 EXISTS 替换 DISTINCT
--优化前
SELECT DISTINCT USER_ID,BILL_ID FROM USER_TAB1 D,USER_TAB2 E WHERE D.USER_ID= E.USER_ID;
--优化后
SELECT USER_ID,BILL_ID FROM USER_TAB1 D WHERE EXISTS(SELECT 1 FROM USER_TAB2 E WHERE E.USER_ID= D.USER_ID);
用 WHERE 子句替换 HAVING 子句
用 UNION ALL 替换 UNION
用 TRUNCATE 替换 DELETE
用 EXISTS 替换 IN、用 NOT EXISTS 替换 NOT IN
3.3 表设计优化
水平分区表
见“分区表”
全局临时表
事务型临时表
创建指定临时表是事务级的,每次事务提交或回滚之后,表中所有数据都被删除
CREATE TEMPORARY TABLE TEMP_COMM (C1 INT,C2 INT,C3 DATETIME) ON COMMIT DELETE ROWS;
会话型临时表
创建指定临时表是会话级的,会话结束时才清空表;
CREATE TEMPORARY TABLE TEMP_SESS (C1 INT,C2 INT,C3 DATETIME) ON COMMIT PRESERVE ROWS;
3.4 表的连接方式
见达梦数据库系列-41.表连接方式
3.5 HINT
见达梦数据库系列-43.HINT
4、统计信息
见达梦数据库系列-39.统计信息详解
达梦技术社区:达梦数据库 - 新一代大型通用关系型数据库 | 达梦在线服务平台