【C++_list】理解链表!实现链表!成为链表!!
List
- 1. list的介绍及使用
- 2. list的模拟
- 1)大致了解List框架
- 2)模拟实现List操作
- 3)关于const迭代器的问题(重点)
- 4)关于链表拷贝的问题
1. list的介绍及使用
- 下面会给出list的文档介绍官网,也是本博客的参考网址~
list的文档介绍
- ⭐难点一:list的迭代器与我们往常的迭代器不同
链表是双向迭代器,只支持++ – 不支持 ±
欸?双向迭代器和随机访问迭代器是什么? -> 一张图帮你搞定!

- ⭐难点二:List不支持sort
//记住sort的头文件是这个 --> #include list lt1 = { 1,2,3,4,5,6 }; //定义 sort(lt1.begin(), lt1.end()); //这样写是错误的 🔺在 list 里面,我们是不能使用 sort 进行排序的,这里运用到难点一的知识点:因为sort使用的是随机访问迭代器
其实当我们点开 list 文档发现,他已经帮我们写好了
所以直接调用即可❤(注意,我们现在讲的是list的运用,如何实现在后面很快就会说明)
list lt1 = { 1,2,3,4,5,6 }; //定义 lt1.sort(); 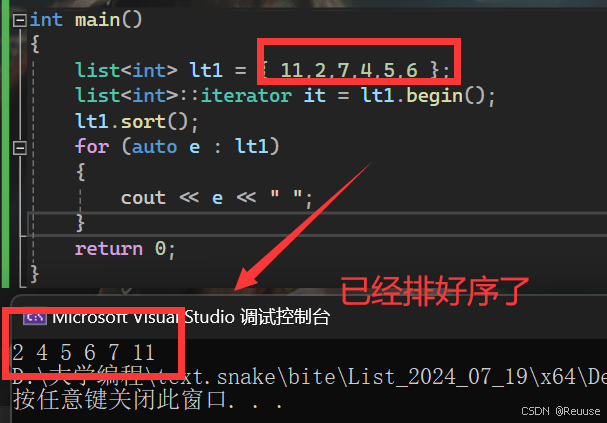
这里有一个需要注意的是,sort默认的算法是升序,如果想要降序的话,我们需要引入一个算法 greater
🔺降序实现方法如下:
list lt1 = { 1,2,3,4,5,6 }; //定义 lt1.sort(greater()); //只需要在这里加上就可以了 - ⭐随机调一个数放到首位

- 找出要放在首位的数
记住:在 List 里面是没有find函数
auto it = find(mylist1.begin(), mylist1.end(), 3) //这里的 3 是我们要找出的数 - 将找出的数粘贴到首位
这里引出一个 splice(可以将链表的一个元素插入到其他地方)
🔺代码实现一下:
std::list mylist1; for(int i = i; i <= 4; i++) mylist1.push_back(i); auto it = find(mylist1.begin(), mylist.end(), 3); //下面便是splice的使用 mylist1.splice(mylist1.begin(), mylist1, it); 在这里 splice 并没有删除链表元素然后在插入,类似于剪切功能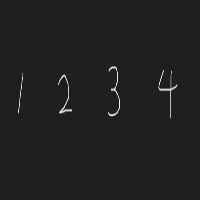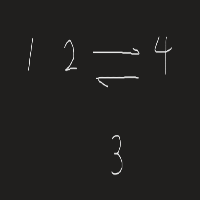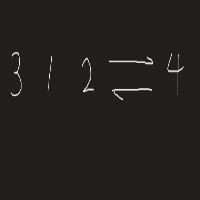
欧克欧克,其实list还是比较简单的,那么接下来我们来实现一下,来加深影响吧!

2. list的模拟
前提是,我们实现的是List的双向带头循环
1)大致了解List框架
实现List的前提是,我们需要弄懂List的内部构造
🔺代码模板可以写成这样
template struct ListNode {}; template class list {}; - ⭐节点包括:指向前一个节点;指向后一个节点;该节点的值
template struct ListNode { ListNode* _next; ListNode* _prev; T _data; }; 注意:为什么是用struct而不是class呢?因为我们在使用LIst的时候会经常访问Node节点,而class默认是私有,所以在访问的时候会报错。(总而言之就是公有私有的问题)
- ⭐链表里面包含一个头指针(头插尾插操作忽略)
template class list { //将ListNode定义为Node为方便后续代码理解 typedef ListNode Node; private: Node* _head; }; 2)模拟实现List操作
具体代码实现方位在如下图位置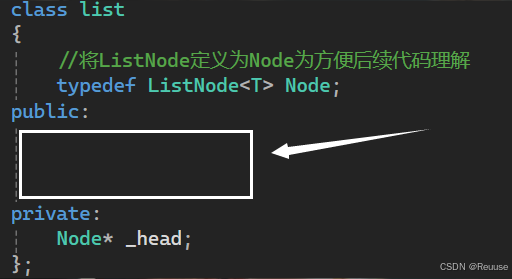
要实现的函数:
1. 构造函数–初始化
2. 析构函数–销毁
3. push_back–尾插
4.insrt & erase – 插入和删除
5. iterator–迭代器
- 构造函数
list() { _head = new Node; _head->_next = _head; _head->_prve = _head; } - 析构函数
~list() { clear(); delete _head; _head = nullptr; } void clear() { auto it = begin(); while (it != end()) { erase(it); } } - push_back
void push_back(const T& x) { Node* newnode = new Node(x); Node* tail = _head->_prev; tail->_next = newnode; newnode->_prev = tail; newnode->_next = _head; _head->_prev = newnode; } 
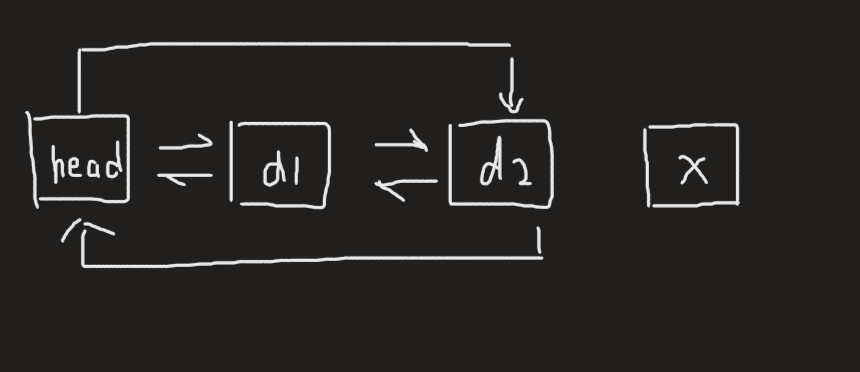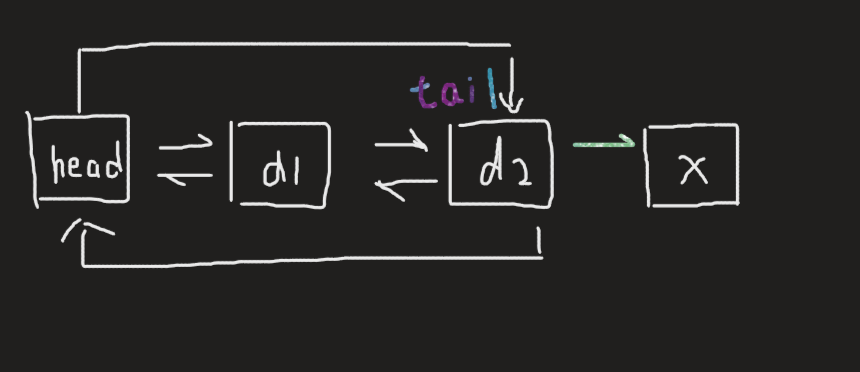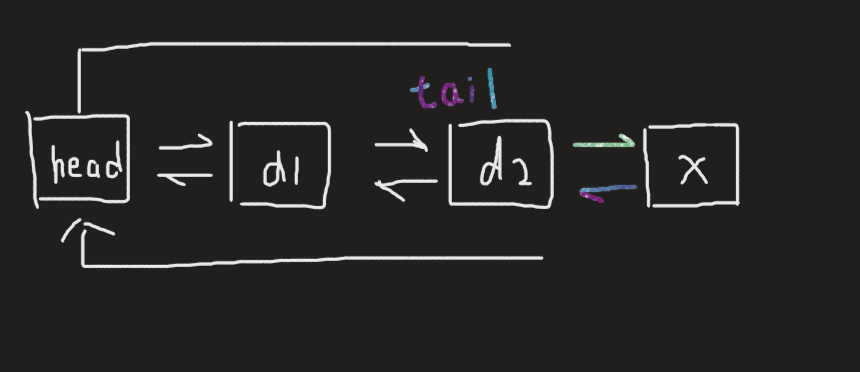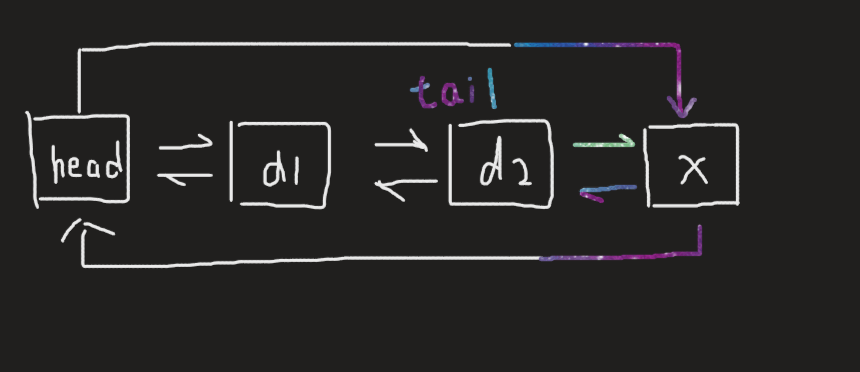
注意:即使是在空链表只有头节点的情况下也同样适用
- 问题一:目前我们已经初步的实现了 List 但是我们在调用的时候会出现报错

- 加入ListNode 的默认构造
ListNode(const T& data = T()) :_next(nullptr) ,_prev(nullptr) ,_data(data) {} - 加入匿名对象,是之初始化后不是空
list() { _head = new Node(T()); _head->_next = _head; _head->_prev = _head; } - insert & erase
- insert:在pos节点前插入
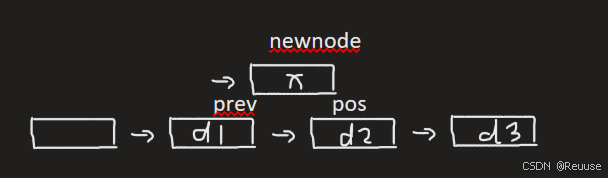
2.erase:在pos位置删除
- insert:在pos节点前插入
⭐代码实现如下
iterator insert(iterator pos, const T& x) { Node* cur = pos._node; Node* newnode = new Node(x); Node* prev = cur->_prev; // prev newnode cur prev->_next = newnode; newnode->_prev = prev; newnode->_next = cur; cur->_prev = newnode; //返回新插入的迭代器 return iterator(newnode); } iterator erase(iterator pos) { Node* cur = pos._node; Node* prev = cur->_prev; Node* next = cur->next; prev->_next = next; next->_prev = prev; delete cur; //有迭代器失效 //erase后,pos失效,pos指向的节点被释放 return iterator(next) } - iterator 重点🔺
在List里面每个节点在物理结构上面都不是连续的,所以单凭迭代器++是无法完成遍历的,所以在这里我们需要单独构造
我们需要一个类来定义迭代器
template class ListIterator {}; - 我们需要搞清楚的是begin和end
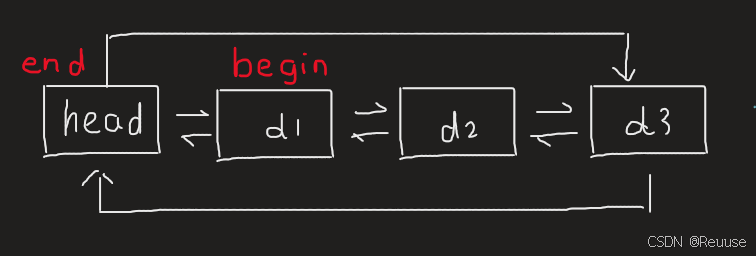
- 这一part比较简单,所以直接上代码即可
/* 当给定的iterator不能满足链表的时候 我们需要自己创建一个新的迭代器 */ template class ListIterator { typedef ListNode Node; typedef ListIterator self; Node* _node; public: //构造函数,给定随机值 ListIterator(Node* node) :_node(node) {} self& operator++() { _node = _node->_next; return *this; } self& operator--() { _node = _node->_prev; return *this; } //前置,返回++之前的值 self& operator++(int) { self tmp(*this); //Self tmp = *this; _node = _node->_next; return tmp; } self& operator--(int) { self tmp(*this); _node = _node->_prev; return tmp; } T& operator*() { return _node->_data; } bool operator!=(const self& it) { return _node != it._node; } bool operator==(const self& it) { return _node == it._node; } }; 
🔺其实是因为List的迭代器不能仅凭 iterator++ 来解决问题(因为地址的随机性)
//随后在class list 里面便可以定义后变成我们所需的iterator typedef ListIterator iterator; 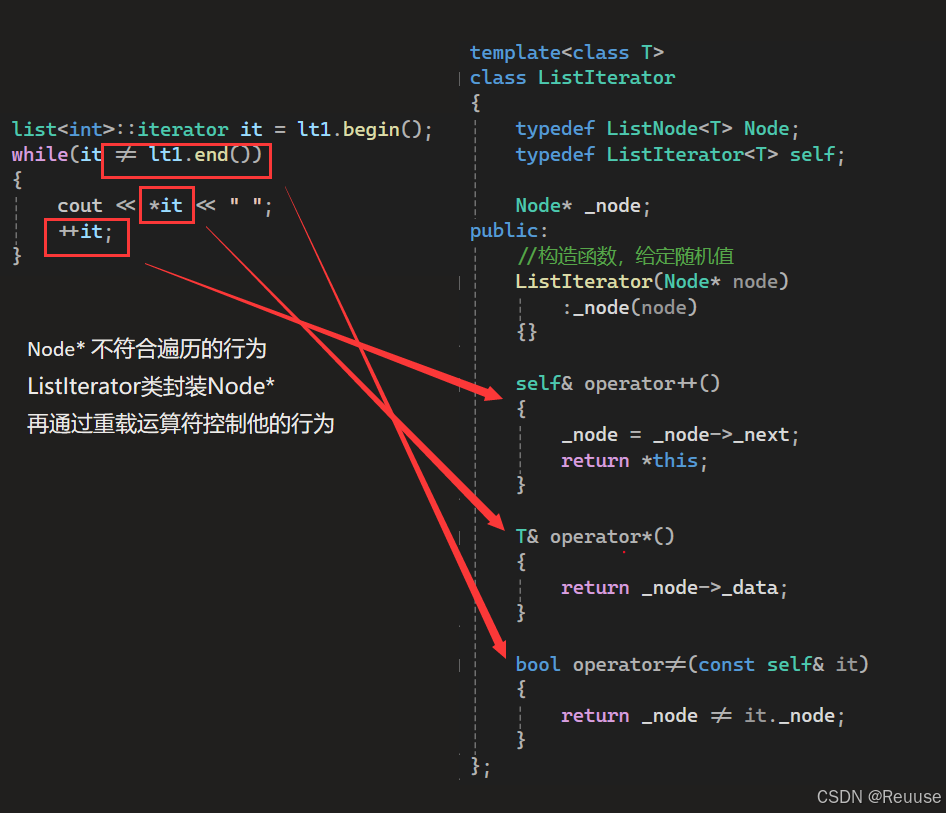
- ⭐难点三:不需要对迭代器写析构函数
迭代器的意义是希望我们去访问或者修改节点,而并不是去删除这个节点,换句话来说,迭代器并不是List的本体,而是一个访问作用的工具。
具象化来说,大体应该是下面这种关系~
- ⭐难点四:不需要拷贝构造(深拷贝)

一般一个类不需要显示的写析构函数,也就不需要写构造函数
3)关于const迭代器的问题(重点)
当我们创建一个const的链表的时候,发现当我们继续遍历链表的时候就会报错,对应的我们需要一个const 的迭代器~

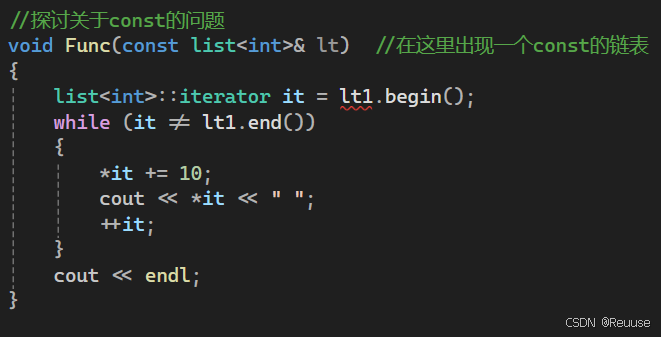
🔺问题二;那么我们怎样才能构造一个const的迭代器呢?
- 误区一:迭代器不能普通迭代器前面加 const 修饰
const iterator const
我们希望const的是迭代器指向的内容不能更改(*iterator),而不是迭代器本身(iterator)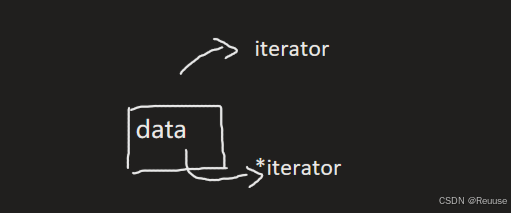
- 🔺其实解决办法也很简答,我们只要控制返回的类型是 T* ,这样就能保证const 的是所指向的值
- 那么这样我们需要多创建一个类
typedef ListIterator iterator; typedef ListConstIterator const_iterator; 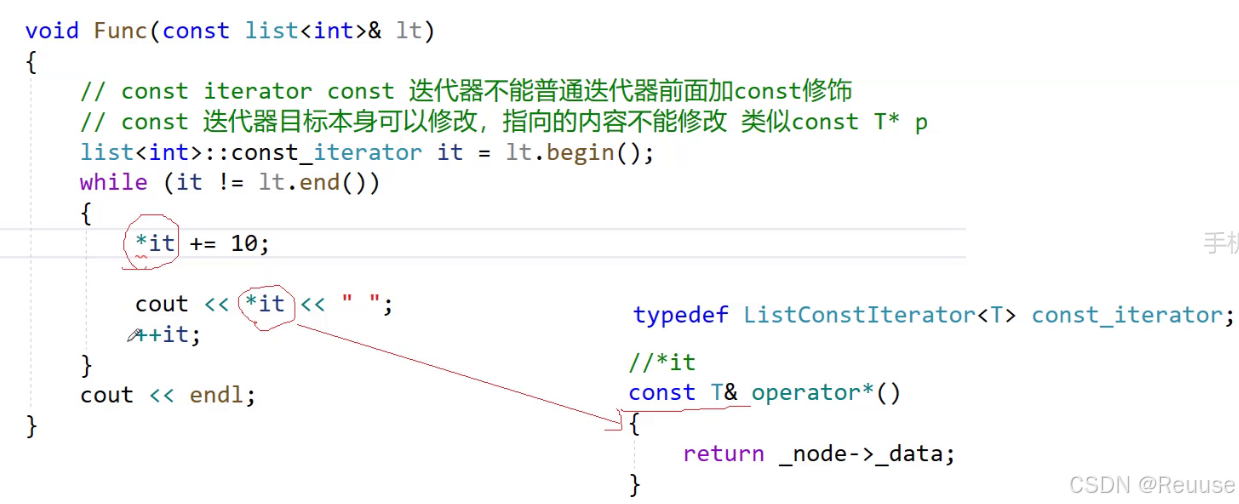

他们的区别就只有一点: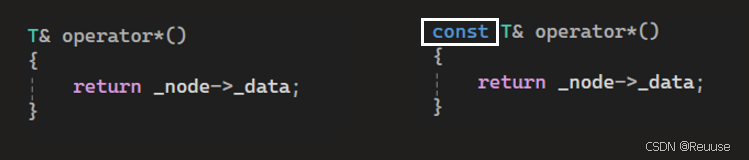
其他的代码部分都是一模一样的
既然这样的话,我们可以有第二种方式,这里就放一张图让大家理解一下:
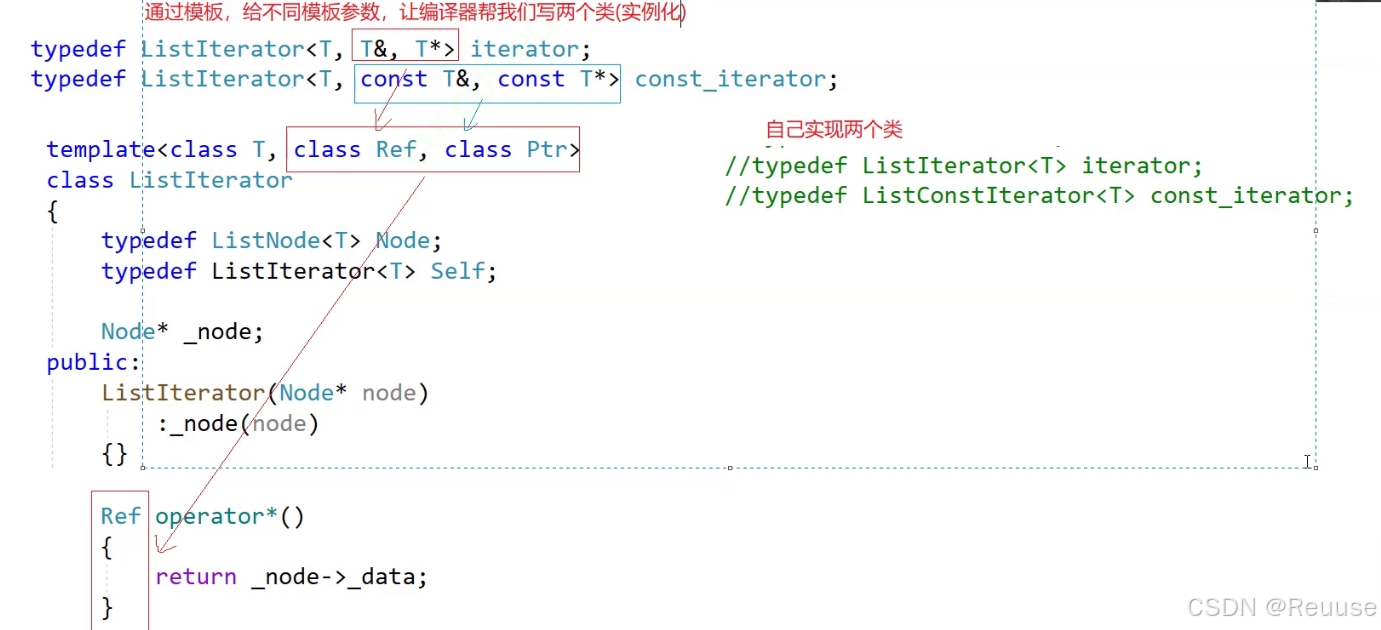
上面的代码大大减少了代码的重复率,使之一份代码可以二次使用
4)关于链表拷贝的问题
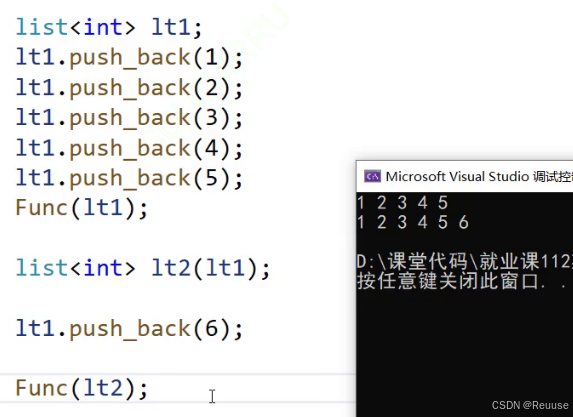
由于默认拷贝构造是浅拷贝,所以我们很容易遇到这样这个问题
我们创建一个 lt2 ,当 lt1 插入一个数的时候,lt2 也插入了
此时两个链表是共享的而不是互相独立的

⭐深拷贝代码实现
list(const list& lt) { _head = new Node(); _head->_next = _head; _head->_prev = _head; for (auto e : lt) { push_back(e); } } 感谢大家的支持,这次暑假过后也有很多事情耽搁了博客
如果喜欢的话请多多支持我